On Linux systems (including real time ones with PREEMPT-RT), C programs allocates memory using the system libc, usually using malloc(). On modern systems, the dynamic memory allocation uses the principle of overcommit. This is based on MMU and the interruption generated when accessing non-mapped memory (or mapped memory with wrong flags, like write on read-only page).
When this principle is applied (not for each allocation), the memory is not really reserved. The definition of the allocation is simply stored until the first write access into the memory. The writing generates a page access fault, and it is during its handling, that the real mapping is made.
Dynamic allocations in a userspace program
The minimum piece of memory managed by the kernel (and by the hardware MMU) is a page. Nowadays, the page size is generally 4096 bytes. This value is important as it is one threshold used by the libc to ask memory to the kernel.
To be able to provide smaller allocation, the libc manages memory pools and dip into it to satisfy program requests. If the current state of the pools cannot provide enough memory, the libc requests a new page to the kernel. The syscalls used (and the associated flags) depend on the asked memory size , on the libc internal pools states, on a few environment variables and also on the system configuration.
When using malloc(), three cases are possible :
- Either the libc returns the asked memory without issuing any syscall, for example for small allocation where libc returns usually a fastbin from the fastbin pool.
- Either the libc uses the sbrk() syscall : it increases the process heap size (or decreases it if a negative value is given)
- Either the libc uses the mmap() syscall : a new memory mapping is added to the process (virtually)
Whichever the method, the kernel always tries to provide memory which is not really physically reserved (also called virtually reserved). So, for a userspace task, there are :
- RSS memory space (resident) : this is the real memory used and dedicated to this program
- VSZ memory space (virtual) : this is the virtual memory which may not have physical space associated yet. For dynamic memory allocation, this is all the page which have not been written yet and will eventually be converted in resident memory on first write on page fault exception.
Each sections of a binary program can use non-resident memory. When using fork(), for writable memory like the ".stack" section, the new memory is simply mapped over the original one with each page tagged as copy-on-write. For read-only memory, both mappings (parent and child) reference the same physical memory. We can note here that, a lot of memory access (even in the stack) may trigger a page fault, not only the heap memory.
There are two kinds of page fault, the minor ones and the major ones. The difference between both is whether an I/O operation (usually a disk access) is required to satisfy the page fault handling or not. A disk access happens when a file is memory-mapped (using mmap()) and then accessed or when a resident page is swapped (backed up on the disk). The latter case never happens on RT systems as swap space is deactivated and system memory is controlled to always be low..
This article only focuses on the dynamic memory (a.k.a. heap) allocation which may not be resident on allocation and the use of the minor page fault.
MMU management overview
The following image (from Jonathan Anderson, checkout his awesome courses here) shows both hardware and software parts of a page fault handling.
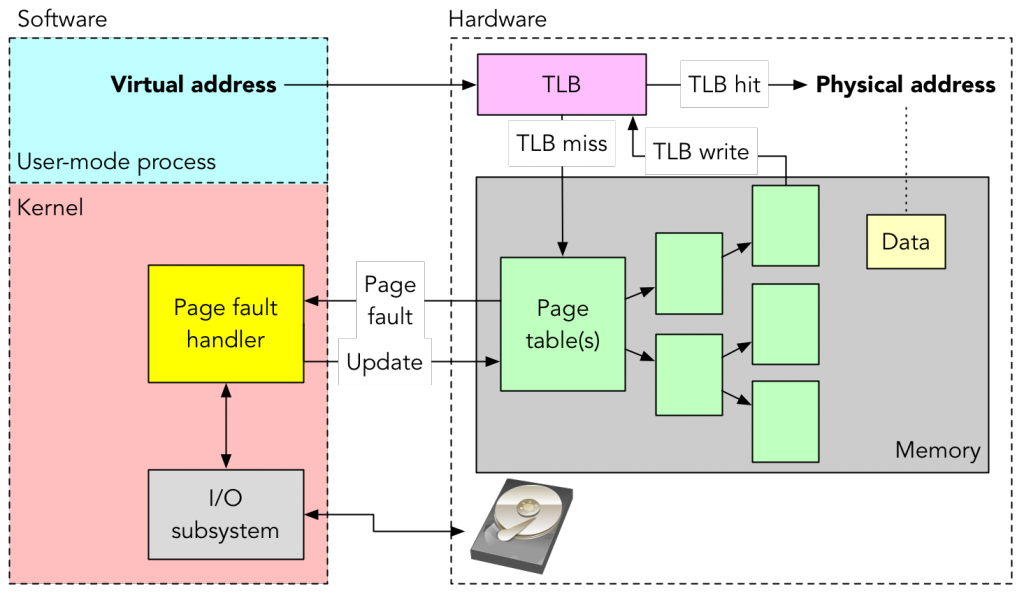
We have seen that a page fault triggers a small piece of code in exception context. It is this code which adds a new memory mapping. But to really understand what is done to add a memory mapping, we have to know how it is implemented.
As shown in the previous picture, the two main features of a processor for memory mapping are :
- The ability to walk a page table to find a physical address from a virtual one
- The TLB (Translation Lookaside Buffer) cache
Both are hardware-implementation and the software is adapted to what the processor can do. So, the way these two HW parts are managed in Linux is architecture-(even CPU)-dependent. The following describes how memory mapping is done on x86 and x86_64.
The page table
A page table is a data structure stored in RAM. There is one mapping per process in the Linux kernel. The kernel itself has its own page table. If, for each process, we have to map one virtual address with one physical address, the memory mapping itself will fill the whole memory ! Several mechanisms allows to limit the memory usage (of the mapping) and to takes advantages of HW caches :
- The memory is mapped per page, not per byte. For example, one entry in the page table maps 4096 bytes.
- To take the memory usage low, virtual addresses are splited in 4 or 5 parts, each is an index inside a intermediate table called directory
- A processor register is dedicated to the first level directory. On x86, this is usually CR3.
The following image describes how a processor translates 64-bit virtual addresses using those directories with 5-level.
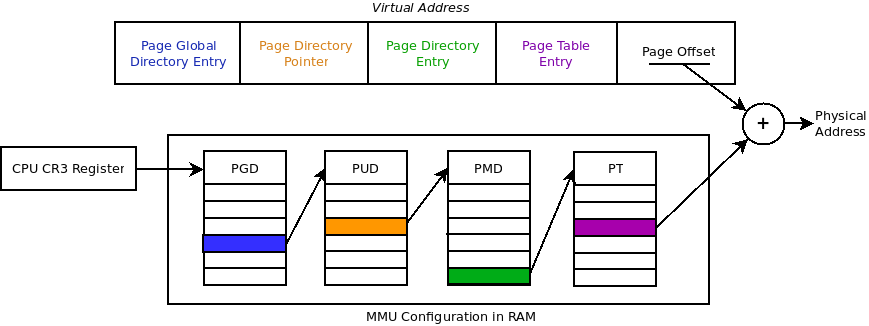
Linux ussually use 4 levels with the directory names : PGD - PMD - PTE (+ offset inside a 4096-byte page) as explained here.
So, in order to translate an address, the processor needs to walk through the pagetable of a process. and it has to fetch each directory entry. This could be quite expensive because the address of one directory is stored in the previous directory level.
The TLB
In order to speedup the process of translating PGD+PMD+PTE -> physical page, the processor has an additional cache called TLB (Translation lookaside buffer). It only stores the result of the translation process (page-based as the virtual memory inside a page is contiguous). This internal cache is independent of the I-Cache and the D-Cache.
The kernel is able to flush the TLB after each modification of the pagetable. When the translation between physical to virtual address of the page are in TLB, the kernel has to modify all internal mapping of the memory, for its own maps and for the user's maps, and the D-Cache must be flushed too. The last operation concerns the IO mapping, that the kernel must reorder.
The TLB cache management inside the Linux kernel is described in cachetlb.txt.
Minor page fault impact
As you could have guess, overcommit is here to reduce real memory consumption and to speedup process creation. But this comes with a downside during runtime : the time taken to access a non-resident memory is a lot longer.
It can be difficult to measure time of faults handling as we need to make sure to use the overcommit principle during an allocation, which strongly depends on libc implementation. Here is a method to do that : we can use posix_memalign()function to allocate million of pages as in the code bellow. This function is recommended to trigger page faults because mmap() is optimized to prevent from triggering lot of page faults (for example by using bigger page or allocating several pages at the same time). The program userfaultfd from kernel source code also uses this function to trigger page faults.
unsigned char* mem_alloc_untouched(int size)
{
unsigned char *buffer;
int ret;
ret = posix_memalign((void**)&buffer, size, size);
if (!ret || !buffer) {
perror("memalign");
}
return buffer;
}To be able to release memory using free() (which does not have a size argument), libc allocates more memory before the address returned by posix_memalign() (same goes for malloc()) in order to store a header where the size is stored (but not only). As posix_memalign() returns an aligned address, an additional page is used before to store the header which becomes resident during allocation because data are written in it (for allocation metadata). This is why, after allocations, we will see page faults (which are not on allocated memory but only for libc chunks header).
/* Initialize our table of pages */
allocated = malloc(PAGES_USED * sizeof(void*));
memset(allocated, 0, PAGES_USED * sizeof(void*));
for (i=0; i<PAGES_USED; i++) {
allocated[i] = mem_alloc_untouched(page_size);
}
/* Here we have reserved a page but no MMU config is done
* First access of each page will trigger a PF
* To ensure this is the case, PF are counted and compared to the number of expected PF
*/
getrusage(RUSAGE_SELF, &usage);
initial_minpfs = usage.ru_minflt;
initial_majpfs = usage.ru_majflt;
/* Trigger PAGES_USED page faults */
t1 = rt_gettime();
for (i=0; i<PAGES_USED; i++) {
touch = allocated[i];
touch[page_size/2] = 0xff;
}
t2 = rt_gettime();
duration_us = t2 - t1;
/* Check new numbed of PFs, diff should be PAGES_USED */
getrusage(RUSAGE_SELF, &usage);
current_minpfs = usage.ru_minflt;
current_majpfs = usage.ru_majflt;
printf("Touching %d pages took %lldus with %d page faults\n",
PAGES_USED, duration_us, current_minpfs-initial_minpfs);The above program shows that one million of page faults happen when we write data in each allocated page during runtime without any syscall. This mechanism is only based on hardware page fault exception. We can count page fault using getrusage()which returns page fault counters (minor and major) among others.
Then, we do the same measure with memory locked (no page fault occurs). Note that userspace process can have a limit on the size of locked memory (see ulimit -a) which may prevent the usage of mlock() with a big size. This will print the following on an i9-based machine :
Using 1048576 pages of 4096 bytes
Touching 1048576 pages took 1682093us with 1048577 pagefaults
Memory locked, no page will be swapped by the kernel unless explicitly released
Touching 1048576 pages took 28260us with 0 pagefaultsSo we can check that each page has trigger a page fault on first write. Then, a second write to these pages does not trigger any page fault as the memory is already resident. By comparing the two cases, we can compute the overhead of one page fault.
time overhead = 1682093us - 28260us = 1653833us
for one page fault = 1653833us / 1048577 = 1,577216552usOne minor page fault overhead is 1.58us on this platform, which may be insignificant if time constaints are around the millisecond. But, having a big number of page fault may lead to a big overhead. So for realtime program using a lot of memory, the overhead may be huge and preventing them is required.
Also, note that the above test has been run on a server. On my laptop (also i9-based with DDR4), I measured an overhead of 0.77us. So, page fault overhead depends on the kernel and the hardware used. On embedded systems, this overhead may be much bigger.
Preventing pagefaults
On realtime systems, we usually don't care of initiallisation but we want the runtime to be as fast (also as deterministic) as possible. In order to prevent page fault, we have to make sure three conditions are met :
- All memory allocation must be made during initialization
- A page fault is triggered for each allocated page
- No page is given back to the kernel and the kernel does not swap it
The programmer must take care of the first condition during implementation. The two last ones can be managed by mlockall() :
mlockall(MCL_CURRENT | MCL_FUTURE)No allocated page are given back implicity to the kernel after the use of this function. Moreover, if a new allocation is made after that, all new pages trigger a page fault during the allocation and not when a first write is made. So, it is very important to allocate memory during initialization when the memory is locked because allocation functions take much longer than if the memory was not locked (as all page faults are made at allocation).
Also, the programmer must make sure that there is enough memory available (locked memory may be limited - see man setrlimit). As memory mapping is the same for all threads, locking memory also impact all other threads. So, even for threads without the call to this function, the memory will be locked and this may decrease performance of memory allocation.
Any mlockall() in one thread is applied on all other threads. This means that, if we have realtime and non-realtime threads in the same process, all threads will have their memory locked except if the programmer control precisely which range of memory should be locked which could be quite difficult to implement. Indeed, mlock() allows to lock only a range of addresses, so only memory reserved by realtime tasks could be locked that way and other non-realtime threads could still use overcommited memory. Still, using mlockall() makes sure page faults are triggered for all fragments of the thread memory, not only for dynamic allocations.
To monitor page faults during runtime, there are several options :
- With libc function
getrusage(). - From kernel filesystem procfs : /proc/[pid]/stat (field 10 : minor faults, field 12 : major faults)
- The tool
pmap -X [pid]allows to show memory mapping of a PID
Things to know about overcommit
On Linux systems, you can tune the overcommit mechanism with the sysctl vm.overcommit_memory. You may think that disabling it is better for realtime systems but beware that you may not have enough memory if you disable it completely. To use commited memory only on RT application, just avoid page fault by locking memory as described in previous section.
If overcommit is enabled, the system will trigger a piece of code called "OOM Killer" if the system has no more memory left for userspace allocations. Indeed, as malloc() never fail (memory is not really allocated at this time), the OS need a mechanism to handle page faults when the memory is full. When it happens, before allocating a new page, it selects a program based on a score and terminates it. On embedded systems, you should always take care of avoiding OOM Killer as it could terminates an unexepected application. However, you can use the sysctl vm.overcommit_ratio to tune the amount of memory usable by userspace applications. This can be useful to increase it for production and to decrease it for development to estimate maximum memory usage.
Conclusion
This article presented how Linux application allocates memory and how allocations are managed from the OS point of the view. Using overcommit mechanism depends on your needs. As Linux standard configuration tends to speedup generic Desktop (or server) usage, this may not fit with your need if you develop a embedded systems where runtime behavior is important.
However, on most embedded system, dealing with commited memory is not necessary as the overhead time is generally low. You should take care of page faults only if you have heavy time constraints or if your application is doing a lot of memory allocations.
Apart from software development, knowing how memory allocation works is also useful for debugging purposes, to design performance tests and understand the results.
Many thanks to Airbus for giving me the time to write this article.
Resources
- System configuration for memory :
- What every programmer should know about memory :
- https://people.freebsd.org/~lstewart/articles/cpumemory.pdf (Voir chapitre 7.5 "Page Fault Optimization")
- Wiki linux-rt :
- Study on pagefault impact for a math program (quite old) :
- RedHat recommendations for linux-rt :
- Course about memory paging from Jonathan Anderson :
- Kernel documentation about page table :