OpenCL (pour "Open Computing Language") est un standard de programmation parallèle open source conçu par le groupe Khronos. Avant de rentrer plus en détail sur les raisons d'être et le fonctionnement d’OpenCL, nous allons revoir en quoi consiste le calcul parallèle.
Le calcul parallèle.
Certains programmes ont besoin d'exécuter un (très) grand nombre de calculs pas ou peu dépendants les uns des autres. C’est par exemple le cas lorsque l’on souhaite appliquer une modification à tous les pixels d’une image ou d’une vidéo. Il serait alors très peu efficace de traiter les pixels les uns à la suite des autres. Une méthode plus optimale est de réaliser les calculs pour chaque pixels en même temps sur un grand nombre de cœurs de processeur en même temps. On dit alors que les calculs sont parallélisés.
Le calcul parallèle est largement répandu dans le traitement des images où la même opération peut être répétée plus de 2 millions de fois pour une image full HD. Ce nombre peut être multiplié par plusieurs milliers lors du traitement d’une vidéo ou pour du calcul scientifique. Il est donc bienvenu d’optimiser au maximum la moindre opération lors d’un calcul en parallèle. Ainsi, différents modèles de calculs ont été conçus afin d’optimiser ses tâches. Parmi eux, on peut retrouver le SIMD et le SPMD.
SIMD
Habituellement, lorsqu'un programme s'exécute, il réalise systématiquement trois étapes successives pour traiter une donnée (comme un pixel par exemple):
récupération de l’instruction en mémoire ;
décodage ;
exécution.
Or, si l’on souhaite appliquer une ou plusieurs opérations identiques à un grand nombre de données, il est inutile de faire un appel à la mémoire pour récupérer la même instruction à chaque fois. Il est plus efficace de récupérer l'instruction une seule fois. C’est ce principe qu’utilise le modèle SIMD (Single Instruction Multiple Data). C'est un modèle efficace pour les calculs vectoriels où il est courant d’appliquer une même opération sur tous les éléments du vecteur. A l’origine, ce modèle a été conçu pour être utilisé avec un seul cœur qui exécute la même instruction sur plusieurs données en économisant du temps d’accès à la mémoire. L’instruction à exécuter “en boucle” est ainsi stockée dans une mémoire au plus proche du cœur. L’utilisation de ce modèle a été étendue aux processeurs multi-cœurs. Dans ce cas, chaque cœur exécute la même instruction sur des données différentes jusqu'à ce que toutes les données soient traitées. C'est un modèle de calcul parallèle largement utilisé pour traiter les images dans les GPU.
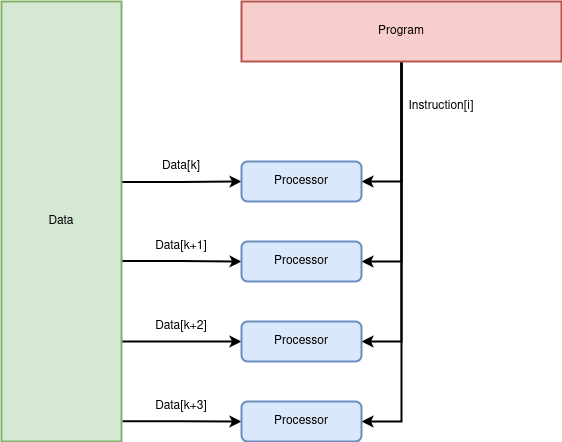
L'efficacité de ce modèle repose sur le fait que l'instruction n’est récupérée qu’une seule fois pour tous les éléments. Ainsi, le temps d’accès mémoire est réduit au maximum. Cependant, ce modèle ne peut pas être utilisé pour des opérations plus complexes comme des conditions car chaque donnée pourrait suivre un chemin différent dans le programme.
SPMD
Si l'on souhaite appliquer une série d'opérations comprenant des conditions, on autorise chaque donnée à prendre un chemin différent en fonction de sa valeur. On peut utiliser un modèle dit SPMD (Single Program Multiple Data). C'est un modèle plus généraliste que le SIMD car chaque donnée peut suivre un chemin différent et donc exécuter des instructions différentes. Il permet d'implémenter des algorithmes plus complexes au détriment d’une baisse de performances. En effet, bien que le programme soit connu à l'avance et soit ainsi placé au plus proche du cœur, il faut, pour chaque donnée, récupérer une instruction potentiellement différente.
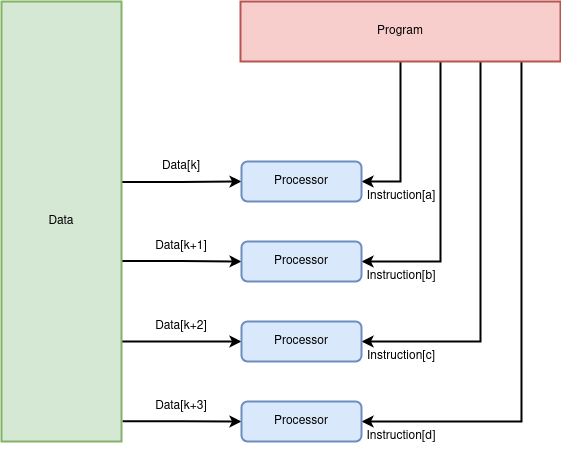
L’utilisation de SPMD et SIMD ne sont pas incompatibles. Lorsqu’il n'y a pas de divergence possible, un programme peut être exécuté en SIMD puis basculer sur un modèle SPMD lorsque les données sont amenées à suivre un chemin différent dans le programme.
La programmation parallèle.
Les processeurs graphiques (ou GPU) sont prévus pour pouvoir traiter un grand nombre de données en suivant les concepts de SIMD et SPMD, ce sont des processeurs avec de nombreux cœurs (de l’ordre du millier) qui peuvent exécuter des milliers de tâches en parallèle. On peut se permettre d'intégrer une grande quantité de cœurs dans ces processeurs car ils sont limités en fonctionnalités. Ce sont des cœurs beaucoup plus lents qui ne sont pas aussi polyvalents que ceux d’un CPU. Ces différences imposent l’utilisation d’un langage de programmation et d’une API différente de celles utilisées classiquement pour un CPU. Les fournisseurs de GPU peuvent fournir une implémentation propriétaire d’une API permettant de faire du calcul parallèle sur leurs produits. C’est par exemple le cas avec Nvidia qui propose à ses utilisateurs de faire du calcul parallèle en utilisant CUDA. Cependant, un programme produit avec une solution propriétaire n’est pas portable. C’est à dire qu’il est impossible d'exécuter un programme CUDA sur une architecture provenant d’un autre fournisseur comme une carte graphique AMD ou un CPU.
Et OpenCL?
OpencL se veut être un Standard de programmations parallèle pour des systèmes hétérogènes. C'est-à-dire qu’il vise à rendre un même code utilisable sur n’importe quel type de processeurs. Ainsi, là ou un programme écrit avec CUDA ne peut être exécuté que sur une carte graphique Nvidia, un programme écrit avec OpenCL peut être exécuté sur tous les processeurs à condition qu’il existe une interface OpenCL adaptée à ce processeur. C’est le cas pour la majorité d’entre eux qui disposent d’une API propriétaire. Par exemple, Texas Instruments met à disposition "TI OpenCL" sur certains de leurs SoC.
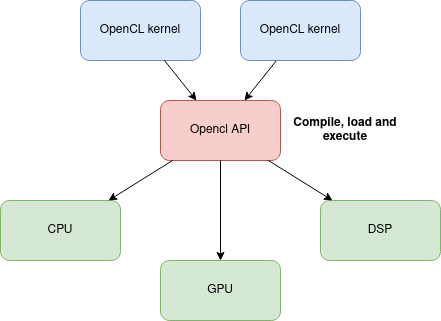
Le fonctionnement d'OpenCL
Afin de réaliser un grand nombre de calculs sur plusieurs cœurs à la fois, OpenCL fonctionne avec des “noyaux”. Un noyau est une fonction qui va traiter les données.
Afin de traiter un grand nombre de données, OpenCL les divise en plusieurs “Work Group” qui sont répartis sur les différentes unités de calcul du GPU.
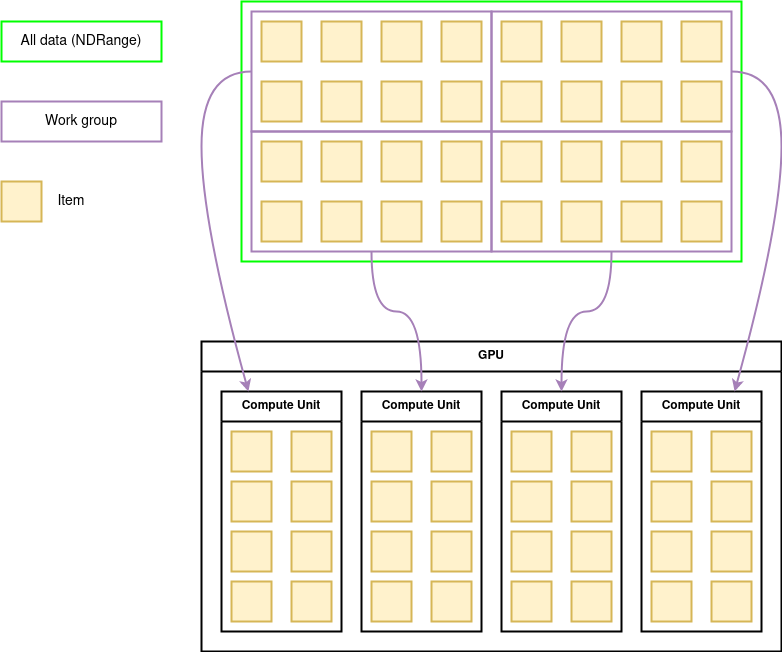
Dans un GPU, chaque unité de calcul est composée de plusieurs cœurs (“processing elements” sur le schéma ci-dessous). Chaque donnée est traitée par un cœur de l'unité de calcul. Il est fréquent qu’un work group contienne plus de données qu’il n’y a de cœurs dans une unité de calcul, les données sont alors traitées les unes après les autres selon les modèles SIMD et SPMD.
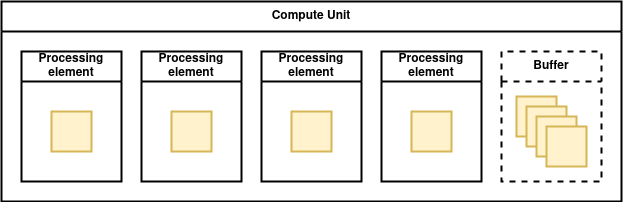
Un programme OpenCL utilise deux API. La première permet au programme de détecter et d’initialiser des cibles (CPU, GPU, FPGA, …). Une fois les cibles initialisées, la deuxième API permet de compiler des noyaux, de les exécuter sur la cible et de communiquer avec eux.
Une API OpenCL est capable de compiler à la volée. C'est-à-dire que le code est compilé au moment de l'exécution du programme. En effet, les noyaux OpenCL sont généralement enregistrés sous forme de chaînes de caractères dans le binaire du programme et compilés lors de son exécution. Cela permet permet à un noyaux d’être:
- Portable: OpenCL a pour vocation d’être utilisable sur tout type de processeur. Dans la majorité des cas, il est donc impossible de connaître à l’avance la plateforme sur laquelle va être exécuté le kernel. C’est l’API OpenCL qui va détecter les différentes plateformes disponibles et leurs caractéristiques afin de compiler le noyau.
- Optimisé: Avant de compiler le programme, l’API OpenCL peut récupérer un grand nombre d'informations sur le processeur cible. Lors de la compilation, il est donc possible de tenir compte d’informations qui ne sont pas connues dans le cas d'une infrastructure générique. Ainsi, le programme peut être performant tout en étant économe en ressource. Par exemple, la taille de la mémoire peut être prise en compte pour optimiser un noyau lors de la compilation.
- Flexible: Il est possible de modifier le code de chaque noyau jusqu’au dernier moment.
- Compatible: Les pilotes peuvent être mis à jour ou modifiés sans risquer de casser le programme.
Si un utilisateur connaît à l’avance la plateforme sur laquelle il souhaite exécuter son programme, il est possible de pré-compiler le code des noyaux. Cela contraint l'exécution à une seule cible. OpenCL n’est donc plus portable lorsqu’il est pré-compilé.
La compilation lors de l’exécution a aussi des défauts. En effet, le driver du processeur doit embarquer un compilateur, ce qui augmente grandement sa complexité. Pour diminuer l'impact de ce problème, il est possible de pré-compiler les noyaux en un langage intermédiaire qui supprime le besoin d’un compilateur frontend dans le driver. Ce langage, conçu par le groupe Khronos, est le SPIR-V. C’est un langage intermédiaire très proche de l’assembleur qui supporte les standards OpenCL, OpenGL et Vulkan. En plus de supprimer la nécessité d'avoir un compilateur frontend dans les drivers il rend le code des noyaux illisible afin de le protéger.
La majorité des drivers GPU propriétaires implémentent une API pouvant traiter du code SPIR-V ou même OpenCL. Mais qu'en est-il des drivers Open Source ?
RustiCL:
Rusticl est un projet intégré à Mesa3D depuis septembre 2022. Il vise à implémenter une API OpenCL écrite en Rust. Cette nouvelle implémentation va remplacer Clover, l’ancienne API écrite en C++. L'intérêt de cette ré-implémentation est double:
- Le design de Clover est reconnu comme étant mauvais. Ce qui entraîne un très faible intérêt de la communauté qui ne prend pas de plaisir à travailler sur ce projet. De plus, ce mauvais design empêche Clover d’atteindre des performances optimales.
- Rust est un nouveau langage avec un grand engouement qui apporte plus de visibilité au projet.
La genèse du projet.
Rusticl à été développé par Karol Herbst. Développeur chez Red Hat et expert de la stack graphique linux. Il souhaitait apprendre le langage Rust et a donc décidé de ré-implémenter OpenCL en guise de projet de découverte. Comme il le dit lui-même, il a développé Rusticl pour le fun: “Implemented OpenCL in Rust for fun” (cf. https://chaos.social/@karolherbst).
Il a choisi OpenCL car Clover n’était presque plus maintenu. En effet, les dernières spécifications d’OpenCL n’étaient pas supportées et peu de drivers étaient compatibles. D’après lui, la principale raison pour laquelle Clover est délaissé est qu’il est écrit en C++ et que la communauté open source se désintéresse de ce langage. Ainsi, une nouvelle implémentation en Rust pouvait apporter de la fraîcheur et de l'intérêt pour OpenCL.
Comment RustiCL traite un programme OpenCL?
RustiCL est une API permettant de faire fonctionner un programme qui suit le standard OpenCL. Son rôle est de:
- détecter les processeurs sur lesquels les noyaux peuvent être exécutés ;
- compiler les noyaux ;
- préparer les commandes à exécuter sur les noyaux ;
- gérer leurs exécutions.
Les drivers open source de mesa prennent en charge le langage intermédiaire "NIR" (spécifique à mesa) mais n'intègrent pas directement de compilateur OpenCL. Or, RustiCL supporte trois formats de noyaux:
- ils ne sont pas compilés ;
- ils sont pré-compilés dans le langage SPIR-V ;
- ils sont compilés au format binaire.
Dans le premier cas, RustiCL utilise Clang pour compiler du code “OpenCL C/C++” en langage intermédiaire LLVM. Créé par LLVM, ce langage peut être traduit en SPIR-V grâce à un outil du groupe Khronos (SPIRV-LLVM-Translator). Le SPIR-V peut alors être linké et optimisé grâce à l’outil SPIRV-Tools, lui aussi fournit pas le groupe Khronos. Enfin, le SPIR-V est traduit en NIR par des outils propres à mesa.
Dans le deuxième cas, le code est déjà pré-compilé en SPIR-V, RustiCL s’occupe alors de le linker puis de le traduire en NIR.
Dans le troisième cas, le format binaire récupéré par RustiCL est du SPIR-V déjà linké qui est simplement traduit en NIR. Ce type de binaire peut être extrait après l'étape de link des deux cas précédents. Cela permet de ne pas avoir à recompiler ou même linker le noyau OpenCL lors de l'exécution du programme.
Voici un résumé des étapes de compilation d’un noyau OpenCL lors de l’utilisation de RustiCL:
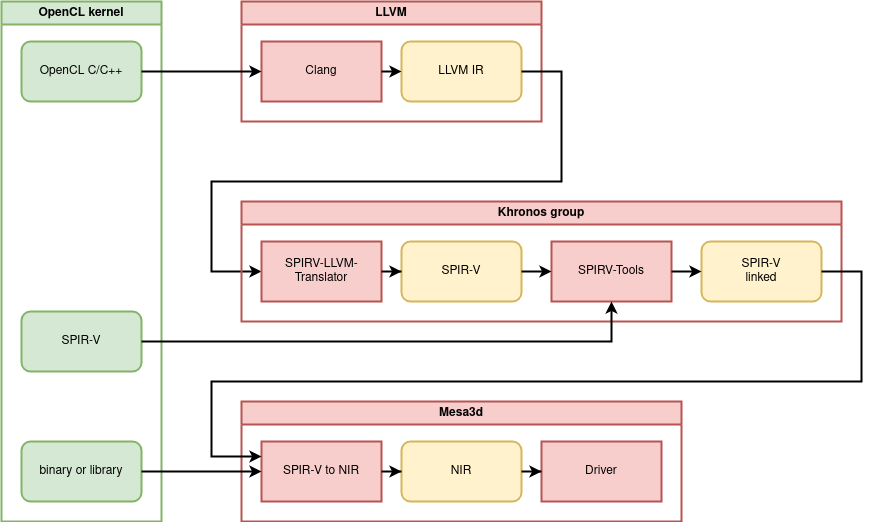
(Le bon fonctionnement de RustiCL dépend de plusieurs outils fournis par le groupe Khronos. Lors de mes recherches j'ai pu remarquer que ces outils ne sont pas présents dans Buildroot. J'ai donc œuvré pour les y ajouter afin de pouvoir utiliser RustiCL dans une image générée avec Buildroot.)
Pourquoi utiliser LLVM et Clang?
Il est commun de traiter le code OpenCL C/C++ avec l’infrastructure LLVM. Dans le guide OpenCL fournit par le groupe khronos, les étapes de compilation des noyaux sont décrites avec l'utilisation de Clang. Le groupe Khronos propose même des outils qui traduises le langage intermédiaire LLVM en SPIR-V.
OpenCL est conçu autour de LLVM pour plusieurs raisons:
- La représentation intermédiaire LLVM est éprouvée quant à sa capacité d’optimisation ce qui est crucial pour du calcul parallèle.
- LLVM supporte le code OpenCL C/C++. Ce n’est pas le cas de GCC.
- Le langage intermédiaire LLVM est traduisible en SPIR-V.
Quels sont les processeurs compatibles avec RustiCL?
Rusticl ne fonctionne pas à lui seul, il faut l'utiliser de paire avec un driver du projet Mesa. Cependant, tous les driver de mesa ne sont pas encore compatibles.
A l’heure actuelle les drivers compatibles sont les suivants:
- Iris: Intel GMA, HD Graphics, Iris ;
- Llvmpipe: Processeurs x86 ;
- Nouveau: GPU Nvidia ;
- Panfrost: ARM Mali Midgard, Bifrost ;
- Radeonsi: AMD Southern Islands ;
- R600 (expérimental): AMD R600, R700, Evergreen et Northern Islands.
La liste des drivers compatible peut être trouvée ici.
Un exemple de programme OpenCL:
Afin de comprendre le fonctionnement d’un programme OpenCL, nous allons étudier un programme simple dont le rôle est d’incrémenter une variable. La première étape est de définir un noyau OpenCL sous forme de chaîne de caractères.
const char *kernelSource =
"kernel void add(global const int *A, global int *B) { *B = *A + 1; }";Dans ce noyau, la fonction “add” prend deux pointeurs en paramètre. “A” pointe sur une constante, c’est la valeur d’entrée qui est incrémentée. La valeur de sortie est stockée à l’adresse de “B”.
Le code d’un noyau OpenCL est très proche du C mais il est est écrit dans une chaîne de caractères. C’est de cette manière que le code du noyau est stocké dans le binaire sans être compilé. Il est possible d’observer le contenu du binaire pour se rendre compte que le code du noyau est toujours lisible dans la section “.rodata”:
$ objdump -s -j .rodata prog
prog: file format elf64-x86-64
Contents of section .rodata:
402000 01000200 00000000 00000000 00000000 ................
402010 6b65726e 656c2076 6f696420 61646428 kernel void add(
402020 676c6f62 616c2063 6f6e7374 20696e74 global const int
402030 202a412c 20676c6f 62616c20 696e7420 *A, global int
402040 2a422920 7b202a42 203d202a 41202b20 *B) { *B = *A +
402050 313b207d 00616464 00526573 756c743a 1; }.add.Result:
402060 2025640a 00 %d..
Dans un premier temps, on appelle une fonction afin d’identifier les périphériques sur lesquels le noyau va pouvoir être exécuté :
clGetDeviceIDs(NULL , CL_DEVICE_TYPE_CPU, 1, &device_id, NULL);Dans ce cas, on demande à l'API OpenCL d’ajouter un CPU dans la liste “device_id”.
Une fois le CPU détecté, on peut récupérer ses informations et les ajouter au contexte :
context = clCreateContext(0, 1, &device_id, NULL, NULL, NULL);C'est cette étape qui permet à un programme OpenCL d’être portable. En effet, les informations obtenues ici vont permettre de compiler le noyau pour la plateforme choisie.
Le code OpenCL peut maintenant être compilé et linké :
program = clCreateProgramWithSource(context, 1, (const char **)&kernelSource, NULL, NULL);
clBuildProgram(program, 0, NULL, NULL, NULL, NULL);Afin de pouvoir compiler le programme pour la cible souhaitée, le contexte et les sources sont regroupées sous la forme d’un objet "program" qui est compilé lors d’un appel à “clBuildProgram”.
Le programme compilé peut contenir plusieurs noyaux. Il faut donc extraire celui que l'on souhaite utiliser :
kernel = clCreateKernel(program, "add", NULL);Ici, un noyau est créé à partir de la fonction “add” du programme compilé.
Maintenant que le noyau est prêt, il faut initialiser les buffers qui permettent d’échanger des données avec lui :
a_mem_obj = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(int), &A, NULL);
b_mem_obj = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(int), NULL, NULL);Le noyaux prend pour entrée une variable constante “A”. On définit donc un premier buffer en lecture seule. Celui-ci va copier la valeur de A pour permettre au noyau de lire sa valeur. En sortie, on définit un buffer de la taille d’un entier en écriture. On pourra y lire la valeur de sortie une fois l’exécution du programme terminée.
Maintenant que les buffers sont créés, il faut définir à quel paramètre d’entrée du noyau chaque buffer correspond :
clSetKernelArg(kernel, 0, sizeof(cl_mem), &a_mem_obj);
clSetKernelArg(kernel, 1, sizeof(cl_mem), &b_mem_obj);
On peut maintenant préparer une file d’attente. Celle-ci permet d’exécuter les noyaux dans un ordre prédéfini lorsqu’il y en a plusieurs :
queue = clCreateCommandQueueWithProperties(context, device_id, NULL, NULL);
On place le noyau dans la file d’attente :
size_t global_dimensions[] = {1,0,0};
clEnqueueNDRangeKernel(queue, kernel, 1, NULL, global_dimensions, NULL, 0, NULL, NULL);Dans le nom de cette fonction, “ND” signifie “N Dimension”. Cela fait référence à la taille des données traitées. Dans notre cas, on a une seule donnée à traiter, la dimension est donc {1,0,0}.
Afin d'exécuter le noyau et d’attendre la fin de son exécution, on peut exécuter la commande suivante :
clFinish(queue);Le programme est bloqué tant que les données sont en cours de traitement. Cette fonction peut être remplacée par “clFlush(queue);” si l'on veut une exécution non bloquante.
A ce stade, le noyau a réalisé l’addition et stocké le résultat dans le buffer de sortie. On peut lire ce qu'il contient pour récupérer le résultat :
clEnqueueReadBuffer(queue, b_mem_obj, CL_TRUE, 0, sizeof(int), &B, 0, NULL, NULL);La valeur de sorite est alors stockée dans la variable B.
Utiliser ce programme avec RustiCL:
L'installation de RustiCL nécessite l'installation des dépendances suivantes :
- cmake ;
- meson ;
- opencl-headers.
Il est possible d’utiliser plusieurs implémentations d’OpenCL à la fois. Pour cela, le groupe Khronos met à disposition l’outil “OpenCL-ICD-Loader”. Voici comment l’installer :
git clone https://github.com/KhronosGroup/OpenCL-ICD-Loader
git clone https://github.com/KhronosGroup/OpenCL-Headers
cmake -D CMAKE_INSTALL_PREFIX=./OpenCL-Headers/install -S ./OpenCL-Headers -B ./OpenCL-Headers/build
cmake --build ./OpenCL-Headers/build --target install
cmake -D CMAKE_PREFIX_PATH=/absolute/path/to/OpenCL-Headers/install -D CMAKE_INSTALL_PREFIX=./OpenCL-ICD-Loader/install -S ./OpenCL-ICD-Loader -B ./OpenCL-ICD-Loader/build
cmake --build ./OpenCL-ICD-Loader/build --target install
mkdir -p /etc/OpenCL/vendors
echo “/your/lib/install/path/libRusticlOpenCL.so” > /etc/OpenCL/vendors/rusticl.icdOpenCL-ICD-Loader permet de définir les implémentation d’OpenCL disponibles dans le dossier /etc/OpenCL/vendors/. Chaque fichier “.icd” présent dans ce dossier contient alors le chemin d’une bibliothèque implémentant OpenCL. C’est pourquoi nous avons écrit le chemin de libRusticlOpenCL.so dans rusticl.icd.
Installation de RustiCL :
git clone https://gitlab.freedesktop.org/mesa/mesa.git
dnf builddep mesa #Selon votre gestionnaire de paquet, cette ligne peut varier. Vous pouvez trouver la bonne commande ici: https://docs.mesa3d.org/install.html#requirements
mkdir build
cd build
meson setup -Dgallium-rusticl=true -Dllvm=enabled -Drust_std=2021 ..
sudo ninja install
Maintenant que l’installation de RustiCL est terminée. Un programme comme celui détaillé dans la partie précédente peut être compilé avec la commande suivante :
gcc -o prog program.c -lOpenCL
Par défaut, les développeurs de RustiCL ont fait le choix de désactiver tous les drivers compatibles tant que certains problèmes de stabilité surviennent. Les noms des drivers à activer doivent donc être définis dans la variable RUSTICL_ENABLE. (Ceux-ci doivent être séparés par des virgules).
Afin d’exécuter le programme sur un CPU x86_64, on peut utiliser le driver LLVMPIPE :
RUSTICL_ENABLE=llvmpipe ./progPourquoi choisir OpenCL?
OpenCL est souvent comparé à CUDA, la solution de calcul parallèle offerte par Nvidia. Cependant, leurs philosophies sont différentes. En effet, OpenCL se veut être un standard portable là où CUDA a été développé pour ne fonctionner que sur les cartes Nvidia. CUDA est donc optimisé pour être le plus performant possible sur ces GPU, ce qui lui permet d'obtenir de meilleurs performances.
Si l’on souhaite obtenir le programme le plus efficace possible sur un GPU Nvidia, CUDA est un choix évident. Cependant, si le projet doit pouvoir s’adapter à plusieurs types de processeurs ou être totalement Open Source, CUDA n’est pas une option viable et OpenCL s’impose.
Conclusion
OpenCL est un standard de programmation parallèle qui peut être exécuté sur tout type de plateformes comme des CPU, des GPU,… Bien qu’OpenCL soit un standard Open Source, la majorité des drivers permettant d’implémenter OpenCL sont propriétaires ou limités. Avec l'essor de Rust, le projet RustiCL a vu le jour et offre une implémentation Open Source d’OpenCL qui est compatible avec plusieurs plateformes. De plus, RustiCL est activement maintenu et vise à supporter de plus en plus de plateformes à l’avenir.