Qu’est-ce que Protobuf ?
Protocol Buffers (Protobuf) est un format de données multiplateforme gratuit et open source utilisé pour sérialiser des données structurées (comme le fait xml, json, etc.) développé par Google. Sa première apparition en public était en 2008, sous sa deuxième version (Proto2).
Protobuf est utile pour développer des programmes dans plusieurs langages et pour plusieurs plateformes qui communiquent entre elles sur un réseau ou pour stocker des données. Il stocke de manière efficace et compacte les données structurées sous forme binaire, ce qui permet un transfert plus rapide sur les connexions réseau.
La méthode consiste à construire une structure de données (définie dans un fichier .proto), puis, à l’aide d’un programme, on génère un code source dans le langage choisi. Ce code source permet de sérialiser ou décoder un flux d'octets qui représente les données structurées.

Dans cet article, nous allons utiliser l’implémentation en C du Protocol Buffers.
Quelle est la différence entre Proto2 et Proto3
Actuellement, il existe deux versions de Protocol Buffers, la version 2, sous le nom de Proto2, et la version 3 (Proto3). D'un point de vue global, on peut dire que Proto3 est une version simplifiée de Proto2. Dans ce cadre, Google garantit la compatibilité du binaire : la même construction dans proto2 et proto3 aura la même représentation binaire. Cela signifie qu'ils peuvent référencer des symboles dans toutes les versions et générer du code qui fonctionne bien ensemble.
Proto3 est la dernière version de Protocol Buffers et inclut les modifications suivantes de Proto2 :
- La présence d'un champ, également appelée « hasField », est supprimée par défaut pour les champs primitifs.
Un champ primitif non défini a une valeur par défaut définie par le langage. - Proto3 n'autorise pas les valeurs par défaut personnalisées. Tous les champs de Proto3 ont des valeurs par défaut nulles et cohérentes.
- Proto3 supprime la prise en charge des champs « required ».
- Proto3 : les énumérations nécessitent une entrée avec la valeur 0 pour servir de valeur par défaut.
Proto2 : les énumérations utilisent la première entrée syntaxique de la déclaration « enum » comme valeur par défaut là où elle n'est pas spécifiée par ailleurs. - Proto3 définit une spécification JSON canonique pour toutes les fonctionnalités alors qu'il n'existe aucune spécification pour diverses fonctionnalités Proto2 telles que les extensions.
Construire un message
Dans la suite de ce document, nous allons nous intéresser à la version proto3.
Imaginons qu’on veut créer un binaire comprenant les champs suivants :
- Message_number : le numéro d’un message à envoyer, de type uint32
- Message_type : le type de message, de type enum
- Message_description : la description du message, de type string
- Timestamp : l’heure du message, de type uint64
- Message_payload: le pointeur sur la donnée à envoyer, de type uint32 *
La première étape consiste à définir cette structure de données dans un fichier, dit le « .proto » :
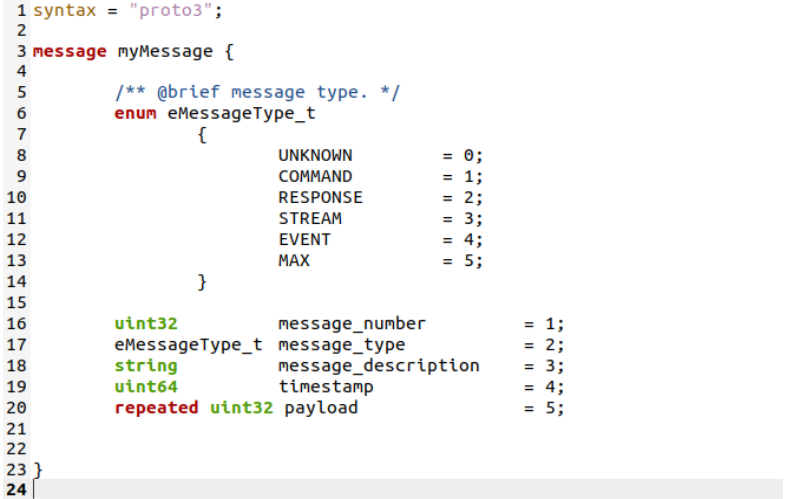
La première ligne de ce fichier, décrit le “syntax”, utilisé pour décrire la version de Protocol Buffers.
Le reste de ce fichier décrit le message:
- Nom de message, situé sur la ligne 3.
- Le corps du message: il peut contenir des énumérations (de la ligne 6 à la ligne 14) , des champs (de la ligne 16 à la ligne 20), etc.
- Chaque champ de ce message, doit avoir au minimum 3 éléments: son type, son nom et son index dans le message:
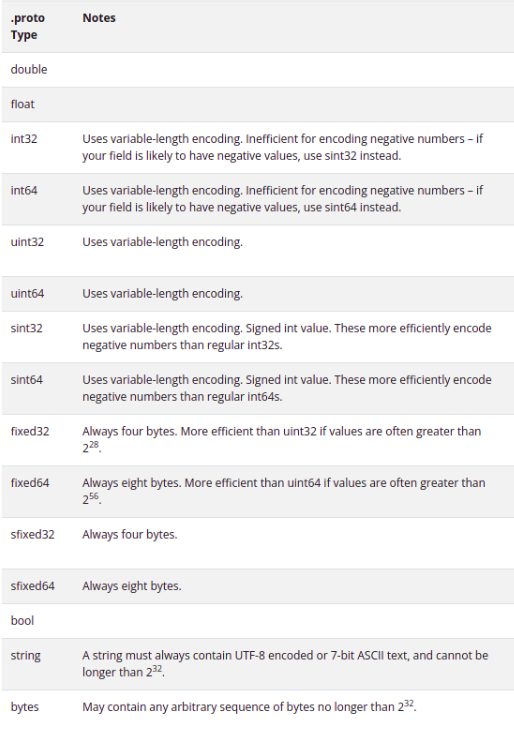
- protobuf supporte les types scalar (voir tableau en bas), on pourra aussi définir nos propres enums, comme dans l’exemple décrit en haut
- l’index doit être unique et compris entre 1 et 0x1FFFFFFF sauf 19,000 à 19,999 qui sont réservés à Protocol Buffers.
On doit utiliser les numéros de champ 1 à 0xF pour les champs les plus fréquemment définis. Les valeurs de numéro de champ inférieures occupent moins d’espace dans le format filaire. Par exemple, les numéros de champ compris entre 1 et 15 nécessitent un octet pour être codés. Les numéros de champ compris entre 16 et 2047 occupent deux octets. - On pourra aussi ajouter des “labels” tel que “repeated” pour indiquer que ce champ doit être répété plusieurs fois. L'ordre des valeurs répétées sera conservé.
On pourra aussi créer un seul fichier .proto contenant plusieurs messages, créer des messages combinés, ou même importer d’autres .proto (via la commande “import”)
Utilisation dans un code C
Lorsqu’on exécute le compilateur de Protocol Buffers sur un .proto, le compilateur génère le code dans le langage de notre choix. Par conséquent, pour avoir des fichiers en C, on lance la commande suivante:
protoc --c_out=. message.protoCette paire de fichiers générés aura le nom suivant selon notre exemple: message.pb-c.c/h.
Analysons maintenant le contenu de ces fichiers générés:
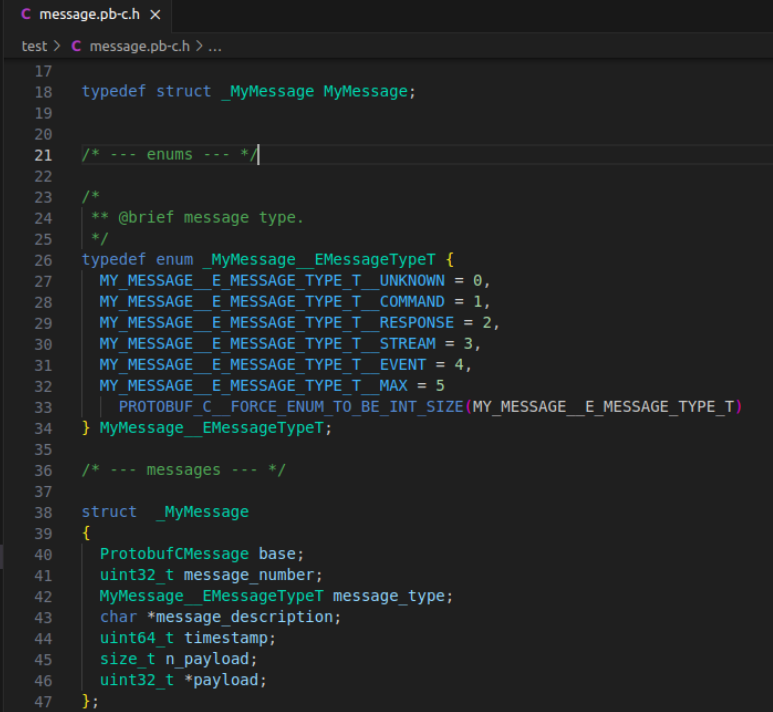
Dans cette première partie du fichier header, on trouve la déclaration de l’enum avec les champs et les valeurs comme présenté en haut de cet article, on voit bien l'apparition d’une macro à la fin de la déclaration de l’enum, il s’agit d’un identifiant présentant le “INT_MAX”
On trouvera aussi, comme décrit dans la figure, la déclaration de la structure myMessage contenant les 5 champs qu’on a définis dans le .proto. Avec ceci, le compilateur a ajouté:
- un nouveau champ: "base": ce champ, comme son nom l’indique, décrit la base de la structure. On doit initialiser dans cette base notre descripteur et le nombre et les noms des éléments inconnus par le parser.
- un deuxième champ, appelé n_payload, qui décrit la taille du payload.
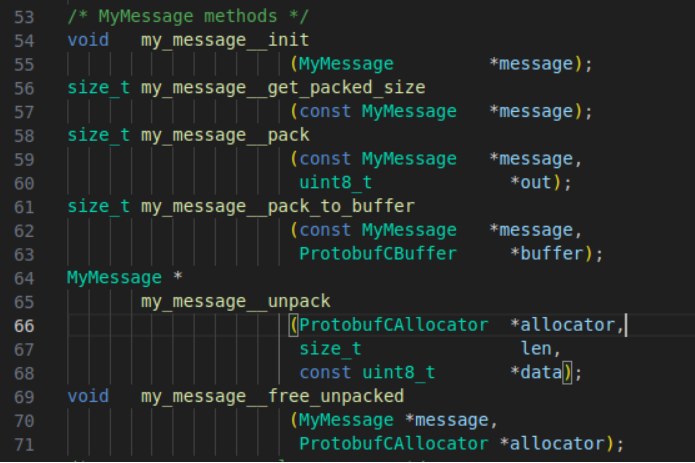
La deuxième principale partie de fichier concerne la déclaration des méthodes à utiliser dans notre exemple d’application. Dans ce contexte, Google met en place un minimum d’API suffisant permettant d’initialiser la bibliothèque, sérialiser et désérialiser un buffer.
Utilisation de Protocol Buffers en C
Dans la suite de cet article, nous allons faire des tests avec ce code précédemment généré par Protocol buffers.
Pour passer sans difficulté l'intégration de Protocol Buffers dans votre programme C, il faut ajouter le code source disponible sur Github ici au projet ou lier le programme avec la "libprotobuf" (par exemple, sur Ubuntu, elle est distribuée par le paquet "libprotobuf-dev"), car le code généré n'est pas complètement autonome.
Initialisation du message
Le premier test qu’on pourra effectuer, est de visualiser le contenu de quelques éléments de la structure avant et après l’appel de la fonction “my_message__init”:
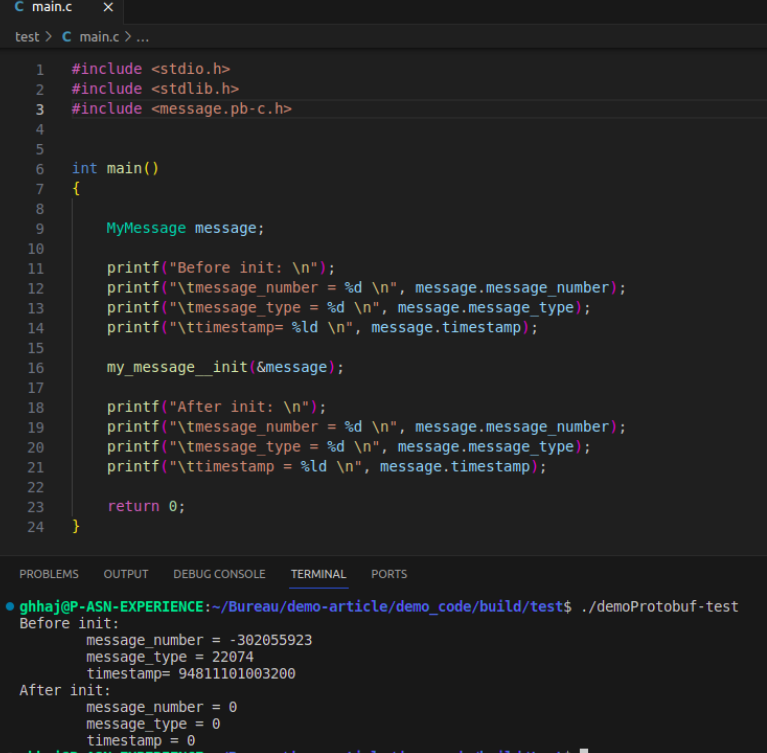
De première vue, il est clair que la fonction Init applique des valeurs par défaut de la structure “message”.
Sérialisation du message
Appliquons maintenant des valeurs dans quelques éléments de la structure, puis, on calcule la taille du message:

Ce code donne le résultat suivant:
Ce résultat donne une visibilité sur la taille nécessaire du buffer à allouer pour faire le pack du message, d'où la suite du code comme le suivant :
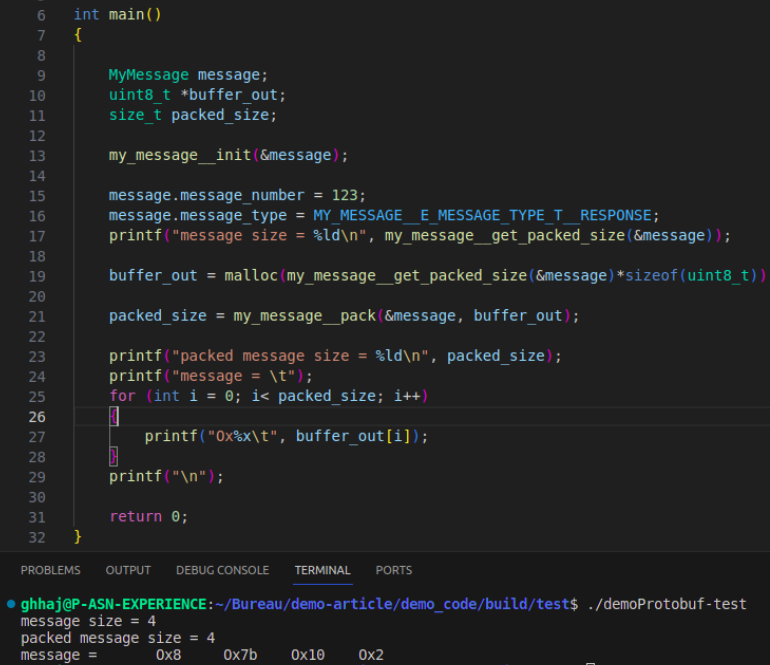
D’après ce code exemple suivant, on pourra conclure que:
- Comme vous l’avez remarqué en haut de ce document, même si le Protocol Buffers ne prend pas en charge les types de taille mémoire inférieure à 4 bytes, la taille du buffer sérialisé ne reflète pas la taille des éléments packagés.
Dans cet exemple, la taille des 2 éléments est égale à 8 bytes, tandis que, la taille du message est bien à la moitié. - On aura pas besoin de packager toute l’ensemble de la structure, Protocol Buffers sérialise uniquement ce qu’on a saisi.
- On aura à l’avance la taille du buffer à allouer pour sérialiser le message
- Le message sérialisé n’est pas lisible humainement, et ne donne pas une visibilité sur le contenu de la structure.
Essayons maintenant de décoder un message:
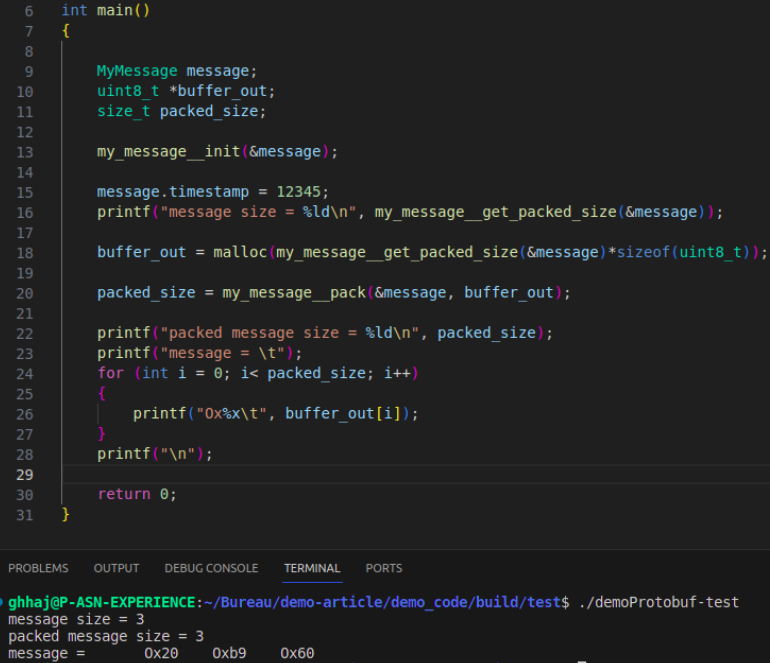
Cet exemple, sérialise uniquement l'élément “timestamp” vers un buffer de taille 3 bytes et de valeur = 0x20B960
Pour rappel:
Timestamp est un élément de la structure “myMessage”, de type uint64_t et d’index 4.
La règle est la suivante:
- Le résultat est sous format: Clé + Valeur
- Le codage de la clé est le suivant: (INDEX << 3) | TYPE
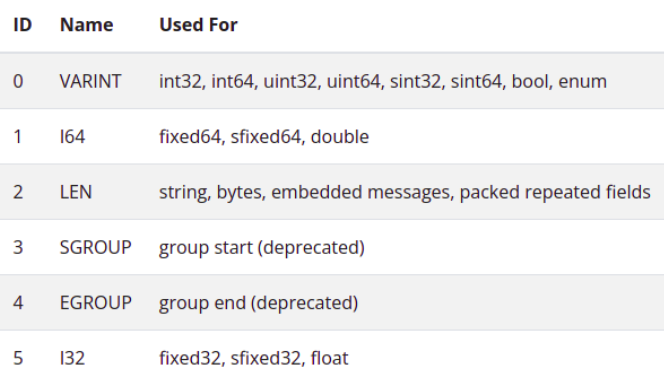
- La valeur de "TYPE" est comme le montre le tableau suivant:
le codage de la valeur : On regroupe sur 7 bits, on ajoute un MSB et on convertit en big-endian.
- MSB de valeur 1 pour indiquer une continuation
- MSB de valeur 0 pour indiquer que c’est le dernier byte
Appliquons maintenant cette logique sur notre exemple:
- la Clé = (INDEX << 3) | TYPE
= (4<<3)|0
= 0x20
d'où la première valeur du message sérialisé. - la valeur = 12345 = 0b11000000111001
= x1100000 x0111001
= 01100000 10111001
= 10111001 01100000
= 0xB960
d'où le reste du message sérialisé.
Décodage du message
Dans la suite de cet exemple, nous allons désérialiser un message et vérifier son contenu.
La fonction “my_message__unpack” nécessite 3 paramètres :
- Un allocateur: structure avec les pointeur des fonctions malloc et free à utiliser lors de la désérialisation du message. On pourra mettre la valeur de l’allocateur à NULL, Protocol Buffers utilisera l’allocateur par défaut: malloc et free de stdlib
- La taille exacte du buffer sérialisé, d'où la difficulté de savoir la taille d’un message sérialisé reçu depuis l’extérieur, sachant que la taille varie selon le contenu du message et aussi des valeurs de chaque élément.
- le buffer à désérialiser.
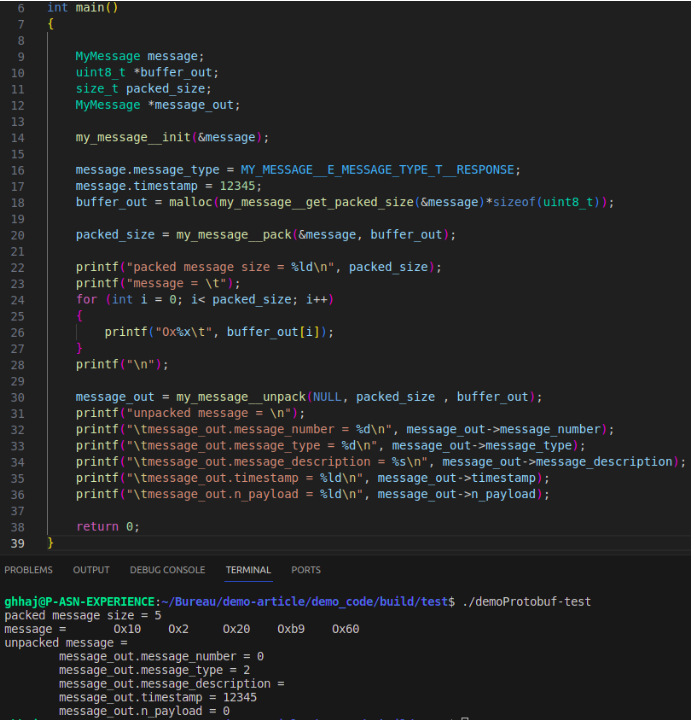
La variable “message_out”, comme décrite dans cet exemple, n’a pas besoin d'être initialisée, le contenu de cette variable va être initialisé dans la fonction “my_message__unpack”.
La fonction “my_message__unpack” met la valeur par défaut des éléments non sérialisés (et non envoyés).
Validation avec la commande protoc
Dans la suite, essayons de valider le comportement de cette librairie en C vis à vis d’autres langages de programmation, et de manière générale via le compilateur de Protocol Buffers lui-même .
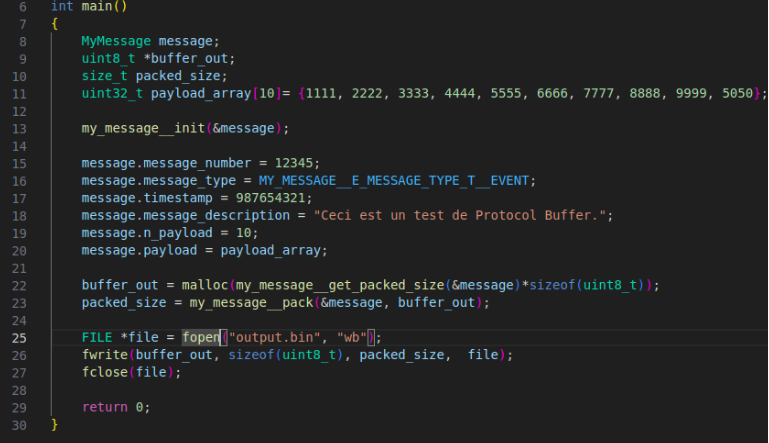
Dans le code suivant, on saisit un message, on le sérialise et puis on le sauvegarde dans un fichier binaire.
Puis, dans un terminal avec la commande protoc —decode, on affiche le résultat de désérialisation via le compilateur de Protocol Buffers.
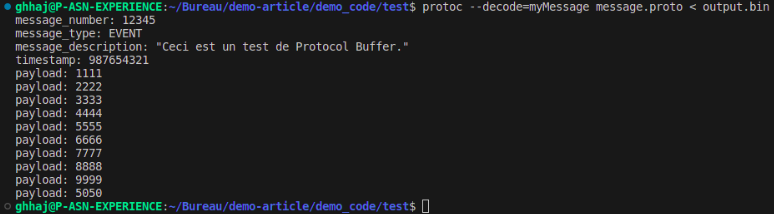
Cette désérialisation avec succès nous garantit la compatibilité avec tous les langages supportés par ce compilateur.
Conclusion
Le format Protobuf offre plusieurs avantages par rapport à d'autres formats. Les données structurées étant stockées au format binaire, elles sont beaucoup plus petites que les formats textuels tels que XML ou JSON, ce qui permet un transfert plus rapide sur les réseaux, et un gain conséquent d'énergie. De plus, Protobuf est conçu pour être facile à étendre, ce qui le rend idéal pour gérer des structures de données qui évoluent rapidement et de nouvelles fonctionnalités. Enfin, le code source spécialement généré à partir de Protobuf peut être optimisé pour la vitesse, ce qui se traduit par des applications plus rapides utilisant moins de mémoire.
Pour information, il existe également des implémentation/alternatives Protobuf dédiées aux micro-contrôleur, qui traite de l'aspect mémoire contrainte de ces architectures :
- https://github.com/nanopb/nanopb
- https://github.com/Embedded-AMS/EmbeddedProto