Introduction
Les outils de profilage permettent lors de l'exécution d'un logiciel de contrôler la liste des fonctions appelées, le temps passé dans chacune d'elle, l’utilisation des ressources processeur ou l'utilisation mémoire par exemple. Sous Linux une multitude d’outils sont disponibles et si vous avez déjà utilisé Perf ou eBPF vous avez sans nul doute remarqué que la quantité de log générée peut rapidement devenir gargantuesque et donc difficilement interprétable.
Cet article va vous présenter les FlameGraph : un outil très pratique de visualisation des logs d’applications profilées qui a été développé par Brendan Gregg, ingénieur chez Netflix et spécialiste de l'analyse de performance. Les FlameGraph sont une une représentation des logs de n'importe quel outil de génération de données de profiling comme eBPF et Perf qui sont également des traceurs déjà introduits par les excellents articles de Jugurtha :
- http://www.linuxembedded.fr/2018/12/les-traceurs-sous-linux-1/ : introduction au traçage et profilage d’applications ainsi que le principe de fonctionnement de Ftrace et ses outils front-end.
- http://www.linuxembedded.fr/2019/02/les-traceurs-sous-linux-2/ : utilisation de perf, avec des exemples de commandes utiles que je vais utiliser dans cet article.
- http://www.linuxembedded.fr/2019/03/les-secrets-du-traceur-ebpf/
Cet article n'est qu'un exemple d'utilisation des FlameGraph précédé de quelques notions. Tout le mérite revient évidemment à Brendan Gregg. Vous pouvez retrouver son blog qui sert de référence aux méthodes de profilage, au lien suivant : http://www.brendangregg.com/overview.html
Génération d’un FlameGraph on-CPU
Une des manières de profiler une application revient à déterminer pourquoi le CPU est occupé. Une façon efficace de faire cela est le profilage par échantillonnage : on envoie à une certaine fréquence une interruption au CPU pour récupérer la stack trace, l’adresse en mémoire de l’instruction en cours d’exécution (Program Counter) ainsi que l’adresse de la fonction. Nous allons dans notre exemple utiliser la commande Perf pour ce faire.
Vous pouvez installer Perf sur votre distribution via votre gestionnaire de paquet : linux-perf sous debian, perf sous CentOS et Arch, linux-tools sous Ubuntu… De plus si vous voulez qu’un utilisateur non root puisse collecter des données dans votre terminal courant, il est possible de modifier la valeur de la variable perf_event_paranoid :
echo -1 > /proc/sys/kernel/perf_event_paranoid.
NB : les programmes que vous profilez doivent comporter des symboles de debug nécessaires à la traduction des adresses mémoire en nom de fonction.
Si vous voulez profiler une application intégrée dans votre distribution via Yocto il faut installer la version « -dbg » du paquet que vous souhaitez analyser. Vous pouvez également utiliser l’image feature « dbg-pkgs » pour créer une version de votre image intégrant tous les paquets de debug ce qui peut être utile pour profiler le système complet.
Sur Debian pour installer des paquets avec les symboles de debug il faut ajouter la source deb http://debug.mirrors.debian.org/debian-debug/ buster-debug main (pour debian buster) dans votre source.list d’apt. Après ça vous pouvez installer les paquets de debug qui ont en général comme suffixe -dbgsym.
Une autre source potentielle de problème peut être que la stack trace retournée est incomplète pour les applications qui sont compilées avec des optimisations de compilation. Dans ce cas il faut recompiler l’application avec l’option -fno-omit-frame-pointer.
De la même manière il est possible que la stack trace du kernel soit incomplète si l’option CONFIG_FRAME_POINTER est désactivée (Kernel hacking/Compile-time-checks and compiler option)
La procédure pour générer les FlameGraph CPU est très simple, il suffit dans un premier temps de lancer la commande suivante pour profiler pendant 30 secondes et à une fréquence de 99Hz (99 interruptions par seconde) une application qui a un PID valant 12345 par exemple :
perf record -F 99 -p 12345 -g -- sleep 30
On peut également profiler le système complet et donc tous les coeurs de la CPU avec l’option -a :
perf record -F 99 -a -g -- sleep 30
Cela va générer un fichier perf.data qui contient les échantillons qui peuvent être lus via la commande perf report :
perf report -n --stdio
Perf est un outil très puissant mais en lançant les 2 dernières commandes sur ma machine, le rapport généré fait plus d’un millier de lignes. Et c’est bien là l’intérêt des FlameGraph. Ils sont très facile à générer et très faciles à interpréter rapidement.
Dans mon cas j’ai généré mes Flame Graphs sur une cible dont la distribution a été générée via Yocto ; voici une recette très simple qui va récupérer les sources du projet et les installer dans la cible :
SUMMARY = "Flamegrah Yocto recipe"
DESCRIPTION = "Flamegraph are a visualization tool for profiled application logs"
LICENSE = "CLOSED"
S = "${WORKDIR}/git"
SRC_URI = "git://github.com/brendangregg/FlameGraph.git;protocol=https"
SRCREV = "1b1c6deede9c33c5134c920bdb7a44cc5528e9a7"
RDEPENDS_flamegraph = "perl"
FILES_${PN} += "flamegraph/"
do_install() {
install -d ${D}/flamegraph
install -m 0755 ${S}/*.pl ${D}/flamegraph
}Vu que rien n’est compilé dans le projet vous pouvez également cloner le projet à l’URI suivant et le copier sur la cible :
git clone https://github.com/brendangregg/FlameGraph
Le projet consiste en une multitude de scripts perl ainsi que des exemples de FlameGraph déjà générés et présentés sur le blog de Brendan Gregg. A partir d'un fichier perf.data généré par perf on peut le copier dans le répertoire du projet et lancer la commande suivante pour générer un flamegraph :
perf script | ./stackcollapse-perf.pl > out.perf-folded && ./flamegraph.pl out.perf-folded > flamegraph.svg
- perf script va chercher dans le répertoire local un fichier perf.data (généré par perf record) et afficher la trace. Attention néanmoins cette commande est dépendante de l’architecture de la plateforme. Il faut donc générer les Flamegraph directement sur la cible.
- stackcollapse-perf va formater la trace en une seule ligne pour qu’elle puisse être traitée par le script flamegraph.pl
- flamegraph.pl transforme le fichier out.perf-folded en une image de flamegraph.
On génère donc un fichier SVG qui peut facilement être ouvert depuis un navigateur. Je vais vous présenter ici un exemple très simple de FlameGraph issu d’un petit programme.
D’une part le programme va dans un premier thread ouvrir un fichier, écrire dedans, le refermer en boucle et va dans un autre thread lancer une boucle vide qui va faire mouliner le processeur. Si on profile le système entier pendant 60 secondes et qu’on lance pendant cette période le programme pendant 30 secondes on obtient le résultat suivant :
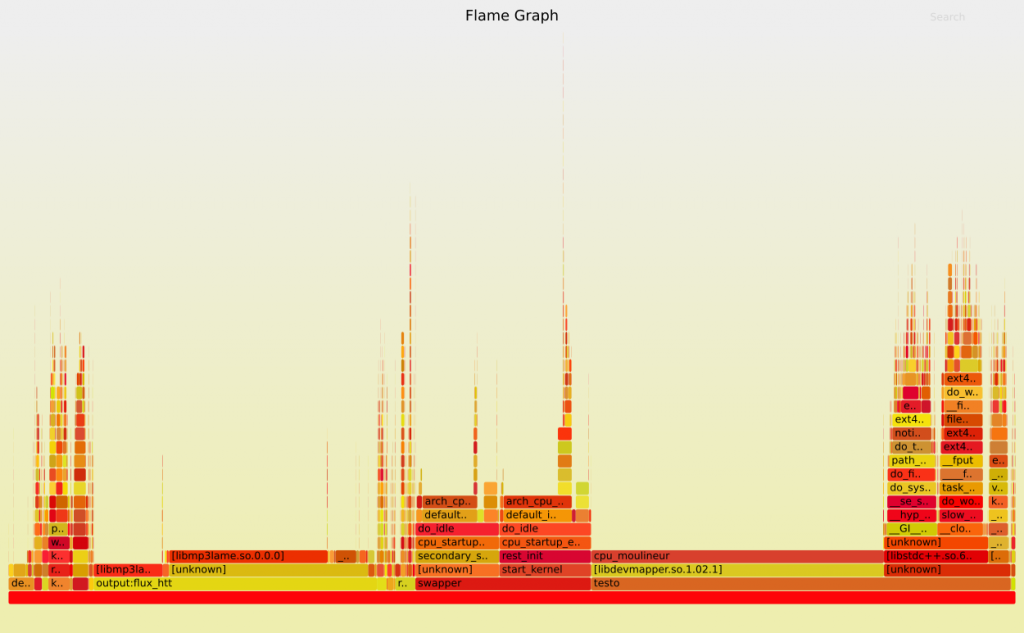
Interprétation du résultat :
- Chaque boite représente l’appel à une fonction dans la pile
- L’axe des ordonnées présente la profondeur de la pile
- La largeur des frame en abscisse correspond au temps passé (nombre d'échantillons) par un CPU à exécuter la fonction correspondante.
Dans notre cas il est très facile de déceler les tâches gourmandes en CPU. Pour interpréter un Flame Graph on va chercher les boites larges tout en haut de la pile et voir par quelles fonctions elles ont été appelées. Ici on remarque que la case « cpu_moulineur » est extrêmement large, c’est elle qui correspond à la fonction contenant une boucle vide.
Si on positionne le curseur de la souris sur la boite « cpu_moulineur » un champ affiche le nombre d’échantillons (et donc le temps passé dans la fonction) ainsi que le pourcentage correspondant par rapport à la mesure complète.
Le bloc situé à sa droite correspond à la fonction qui ouvre et ferme un fichier en boucle. En plus d’observer le nombre d'échantillons pour chaque boite, il est intéressant de voir l’enchaînement des fonctions appelées de l’userspace jusqu’aux strates les plus enfouies du kernel.
Ici l’exemple est relativement trivial mais dans un plus gros projet cela peut s’avérer très utile car les FlameGraph offrent une vision globale des fonctions appelées par une application ! On peut voir par exemple si l’appel à une fonction userspace provoque l’appel à un kmalloc côté kernel.
NB : on ne sait néanmoins pas à quel moment les fonctions sont appelées car il n’y a pas de notion temporelle dans les flamegraph CPU.
D’autres types de FlameGraph intéressants
FlameGraph off-CPU
Les FlameGraph on-CPU permettent de comprendre l’usage CPU mais ne permettent pas de voir les problèmes de latence présents quand un thread est en attente d’une I/O bloquée, d’un timer ou quand il y a un changement de contexte. Cela constitue une forme d’analyse à part entière que Brendan Gregg appelle analyse off-CPU (en opposition à on-CPU).
En résumé l’analyse off-CPU est un moyen de localiser de la latence introduite par le blocage de thread, cette analyse est complémentaire à l’analyse on-CPU et est nécessaire à la compréhension du cycle de vie d’un thread.
Leur génération peut être réalisée via le script offcputime de bcc (je vous renvoie vers l’article de Jugurtha) qui permet de trouver pourquoi et pendant combien de temps un thread est bloqué et ce quelque soit le type de blocage.
Une approche est de tracer les appels aux fonctions malloc et free et afficher sur un Flame Graph le nombre de fois où les fonctions ont a été appelées ou le nombre de bytes qui ont été alloués pour chaque frame.
Conclusion
En résumé le Flame Graph est un puissant outil de visualisation de logs d’outils d’analyse de performance qui peut vous permettre de gagner un temps précieux. J’ai simplement voulu vous partager cette découverte dans cet article qui n’est qu’une rapide présentation, je vous invite une nouvelle fois à vous rendre sur le blog de Brendan Gregg pour beaucoup plus de détails !