Introduction
Les applications et les systèmes d'exploitation sont devenus très complexes, de nombreux outils de traçage sont apparus au cours de la dernière décennie. Leur but est d'instrumenter et optimiser la qualité des programmes en termes de performances et de robustesse.
Après l'article précédent sur Ftrace, nous allons apprendre a utiliser les traceurs Perf et LTTng.
Perf
Perf est un outil d'analyse de performance sous Linux, il peut également être utilisé pour faire des traces. Nous verrons son utilisation dans les deux cas.
Les commandes les plus utilisées de perf
Les options les plus utilisées de perf sont :
- perf list : répertorie les événements pris en charge par perf (événements HW / SW, points de trace).
- perf stat : compte le nombre d'occurrence d'un événement (groupe d'événements ou tous les événements) dans un système ou un programme particulier.
- perf record : échantillonne une application (ou l'ensemble du système) et construit le graphe d'appel des fonctions.
- perf report : analyse et affiche le rapport généré par perf (liste perf ou perf).
- perf script : affiche la trace sous forme de texte afin qu'elle puisse être analysée par d'autres outils.
perf est un outil de profilage
Les statistiques
- Statistique CPU : La syntaxe suivante permet d'obtenir des statistiques sur un programme (gcc dans notre exemple):
$ sudo perf stat ./programme argument_programme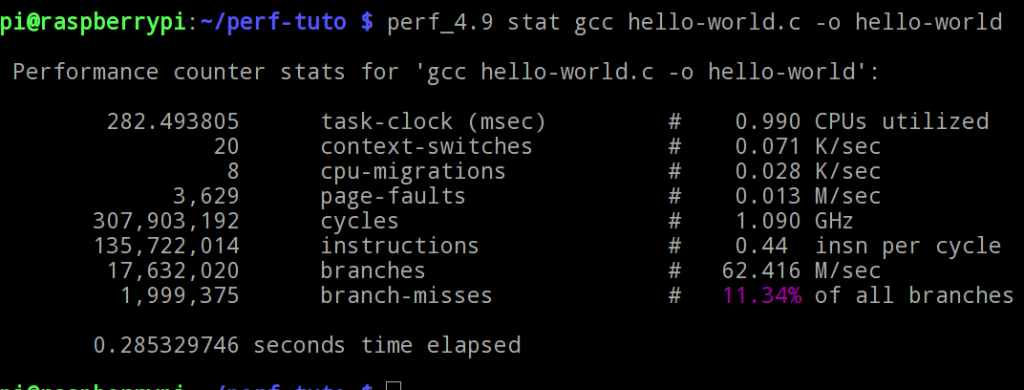
- Filtrer les statistiques : l'option "-e" est utilisée pour filtrer :
$ sudo perf stat -e evenement1,evenementN ./programme argument_programme

Profilage temporisé
Parfois, nous voulons enregistrer le graphe d'appel de notre application et observer les cadres de la pile.
- Phase d'enregistrement :
- Profiler le système en entier : La plupart du temps, nous enregistrons les appels de fonctions et les trames de pile sur une courte période de temps pour l'ensemble du système.

Remarque : Perf produit un fichier perf.data (la commande sleep sert à arrêter les traces au bout de 10 secondes).
- Profiler une seule application :
- Profiler une application qui se termine :

- Profiler une application qui ne se termine pas (Il faut forcer l'arrêt avec Ctrl+C) :

- Profiler une application qui se termine :
- Profiler le système en entier : La plupart du temps, nous enregistrons les appels de fonctions et les trames de pile sur une courte période de temps pour l'ensemble du système.
- Affichage du rapport (parser le fichier perf.data) :
Les rapports sont affichés avec les fonctions triées selon leur temps d'exécution. Une chose qu'on peut visualiser de deux façons :- Mode basique : Nous pouvons utiliser les touches directionnelles pour naviguer, et la touche "Entrée" pour dérouler le contenu d'une fonction afin de voir les appels :
$ sudo perf report -g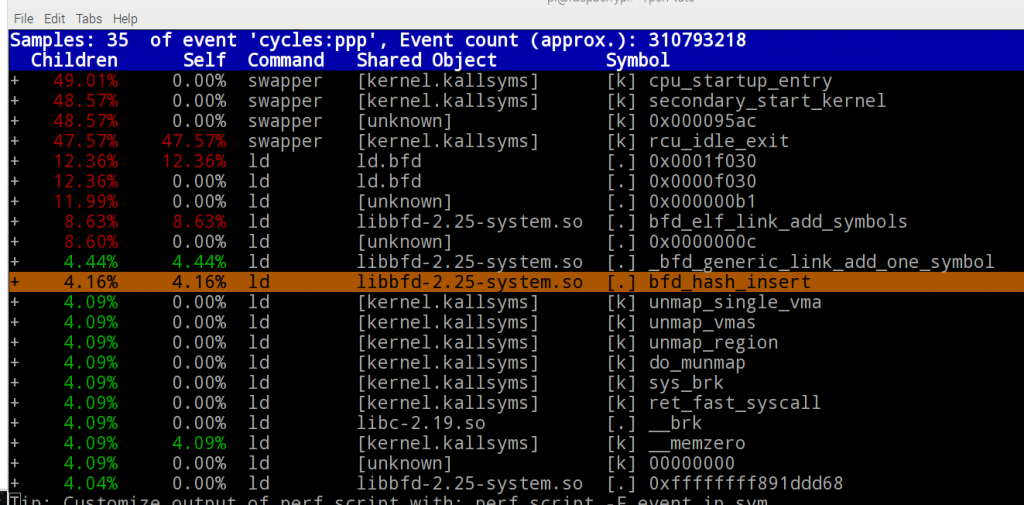
- Mode arborescence : le paramètre --stdio provoque l'affichage du rapport sous forme d'arborescence :
$ sudo perf report -g --stdio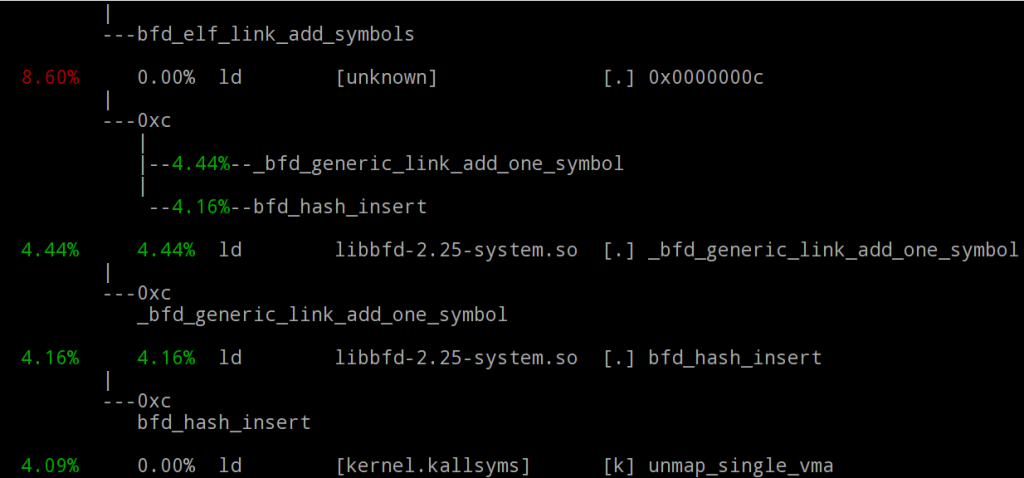
- Mode basique : Nous pouvons utiliser les touches directionnelles pour naviguer, et la touche "Entrée" pour dérouler le contenu d'une fonction afin de voir les appels :

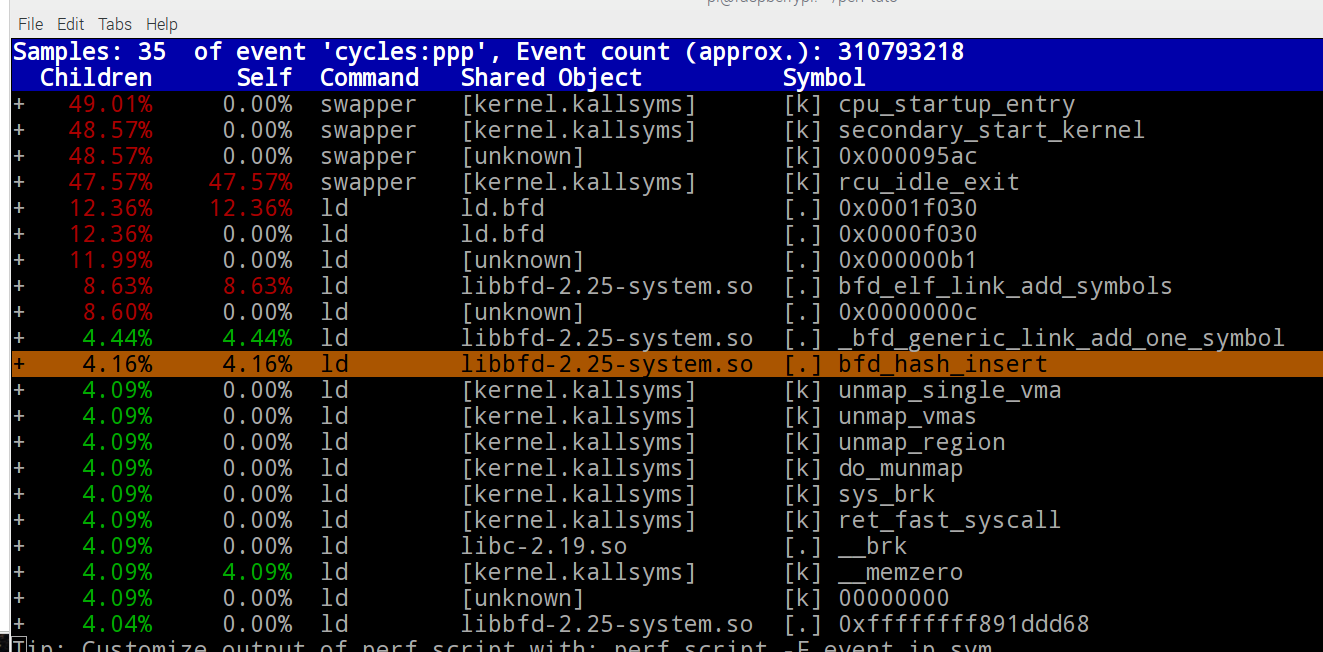
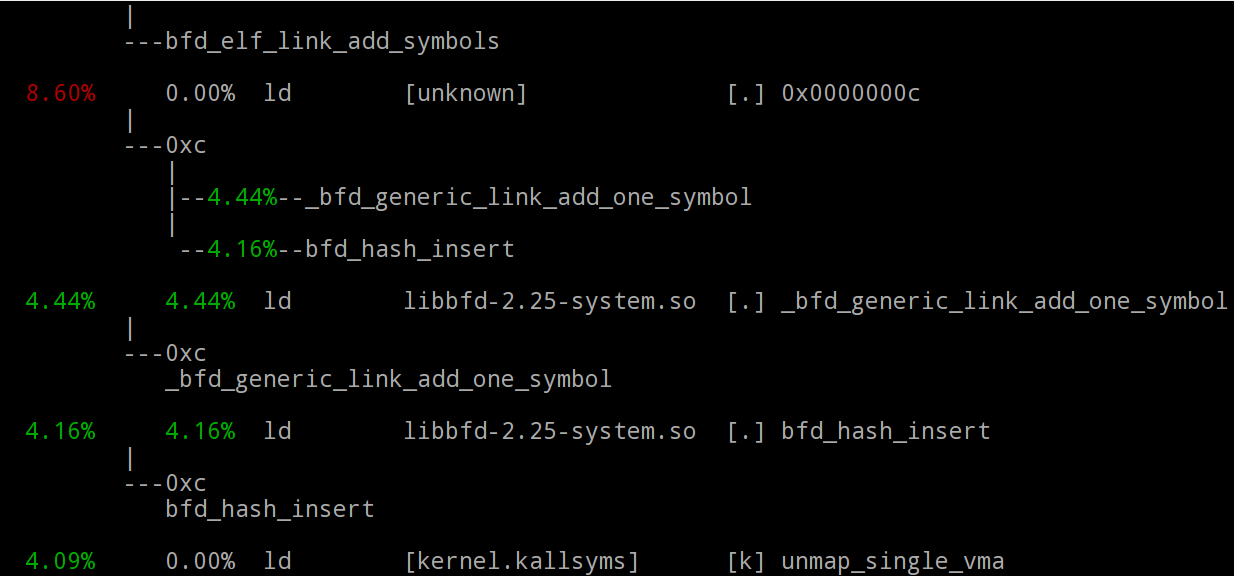
La commande perf report charge implicitement le fichier perf.data qui se trouve dans le repertoire en cours.
Perf est un outil de traçage
Perf a été conçu pour des buts de profilage, mais aujourd'hui il peut faire plus que ça. Nous pouvons l'utiliser pour tracer les fonctions primitives du noyau.
Trouver le nombre secret
Nous allons prendre l'exemple suivant; un jeu qui incite l'utilisateur à deviner un nombre magique (généré aléatoirement), les sources se trouvent à :
https://github.com/jugurthab/Linux_kernel_debug/tree/master/debug-examples/Chap1-userland-debug/gdb/remote-debug/raspberryPI3
Traçage statique
Cela permet de suivre les points de trace qui sont déjà définis et supporté par perf.
- Choisir un point de trace : Nous recherchons dans la liste proposé par perf le point de trace qui nous intéresse.

- Traçage avec perf : La syntaxe générale est comme suit :
$ sudo perf -e point_de_trace1 -e point_de_trace2 -e point_de_traceN [options] [programme]
L'exemple suivant va tracer la fonction "sched_switch" du programme "rpi-number-guess" :
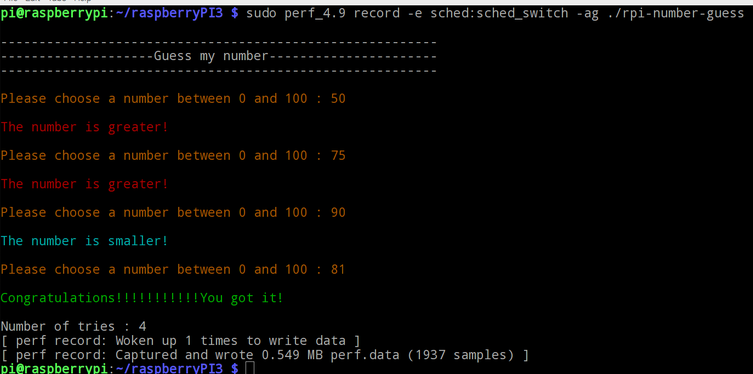
-
- Lecture de la trace : Un rapport de profilage s'obtient avec
perf reportet un rapport de trace avecperf script. La syntaxe générale :
$ sudo perf script [-i chemin_fichier]Rappel : si le chemin du fichier n'est pas fournit, alors "perf script" va essayer de lire le fichier "perf.data" dans le dossier courant.
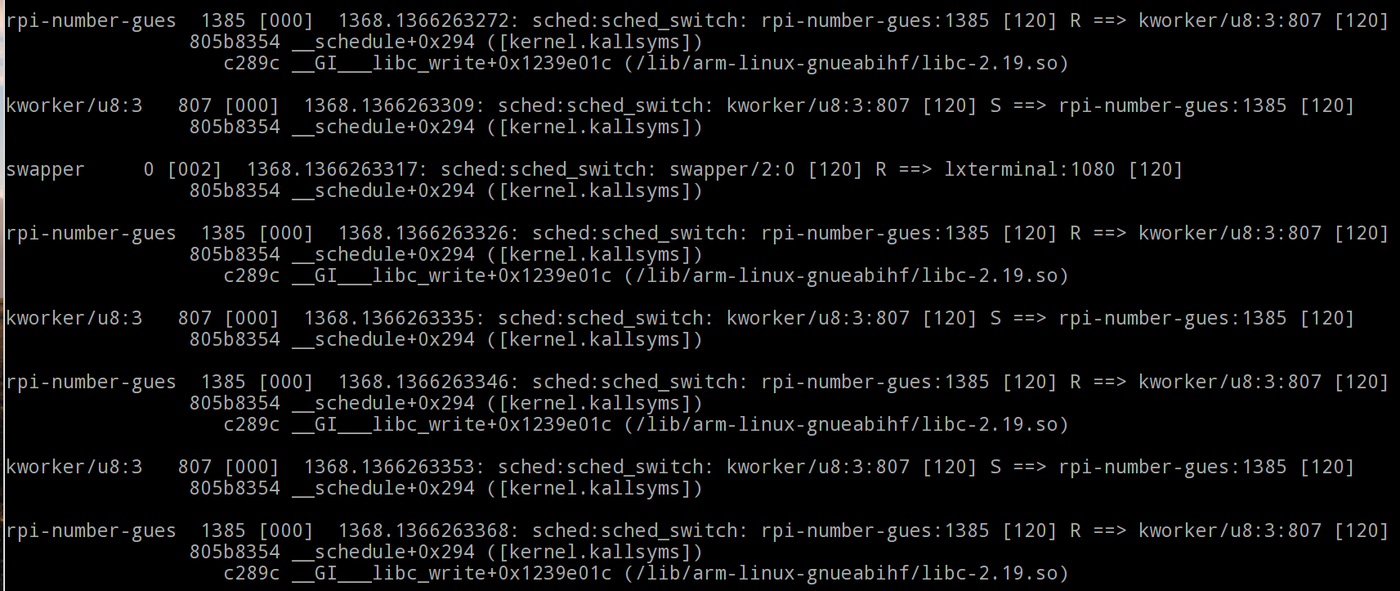
Il est temps de lire la trace obtenue dans l'étape précédente (voir l'image ci-dessous).
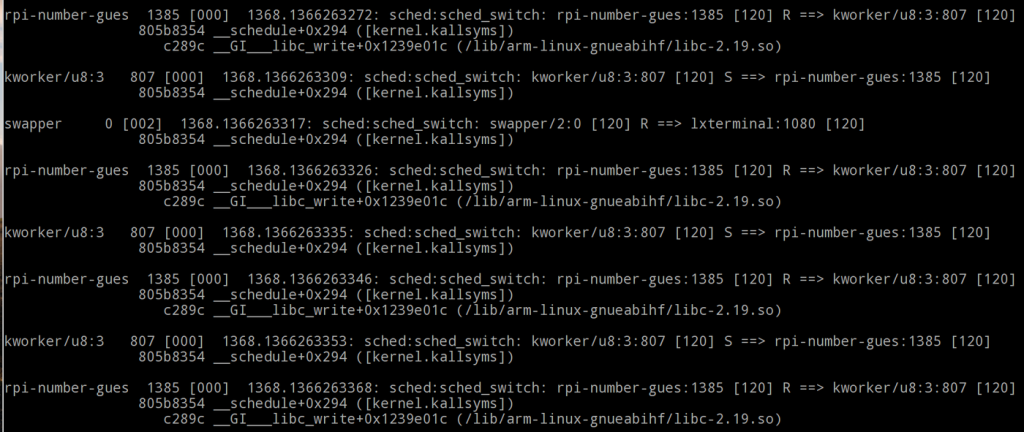
Chaque entrée de l'image ci-dessous est de la forme :
PID [Processeur_Qui_Execute_Le_Programme] Timestamp : fonction_a_tracer: Programme:PID_du_Programme ==> Nouveau processus a exécuter.
- Lecture de la trace : Un rapport de profilage s'obtient avec
-
Traçage dynamique
- Créer un point de traçe dynamique : Créer un événement dynamique signifie étendre la liste des points de trace existants.
$ sudo perf probe --add fonction_a_Tracer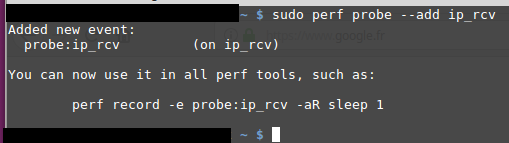
- Traçer l'évenement ip_rcv : (voir l'image ci-dessous).

- Lire la traçe : (voir l'image ci-dessous).

- Supprimer le point de traçe : (voir l'image ci-dessous).

Remarque : Hotspot est une interface graphique pour perf (disponible sur ce lien : https://www.kdab.com/hotspot-gui-linux-perf-profiler), il est capable de parser les fichiers "perf.data" ou même de créer une trace complète.
- Créer un point de traçe dynamique : Créer un événement dynamique signifie étendre la liste des points de trace existants.
-
LTTng
LTTng est une boîte à outils pour la trace et la visualisation des événements produits à la fois par le noyau Linux et les applications. Les traces se font au niveau du noyau (avec un ensemble de modules : https://lttng.org/docs/v2.10/#doc-lttng-modules), les résultats sont plus précis que Ftrace ou Perf et l'overhead est très réduit (pas de changement de contexte).
$ sudo apt-get install lttng-tools
$ sudo apt-get install lttng-modules-dkmsUsage général de LTTng
La façon la plus répandue d'utiliser LTTng se fait comme suit :
- Création d'une session : Chaque trace produite par LTTng doit être faite dans une session.
$ lttng create nom_de_la_session - Choix des tracepoints : Nous pouvons sélectionner un ou plusieurs points de trace. Nous choisirons par exemple la fonction "sched_switch" :
$ lttng enable-event --kernel sched_switch - Démarrer la trace : LTTng va enregistrer tous les événements "sched_switch" (voir l'image ci-dessous).

- Attendre quelques instants (ou lancer les applications que l'on veut tracer)
- Arrêter la trace : la commande "lttng stop" arrête l'enregistrement et crée le rapport de suivi (voir l'image ci-dessous).

- Détruire la session :
$ lttng destroy - Visualiser la trace :
- babeltrace : Nous pouvons voir le rapport LTTng dans la console.
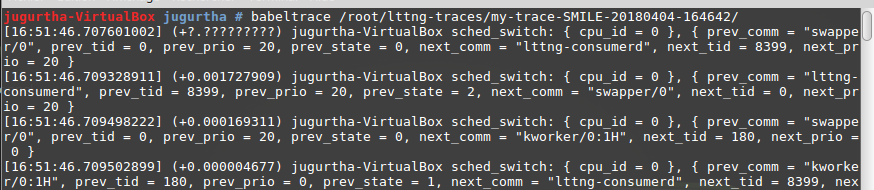
Souvent, les traces sont plus volumineuses et regroupent de nombreux événements, visualiser le résultat en mode texte est loin d'être une tâche aisée.
- Trace Compass : C'est un plugin Ecplise C/C++ (pour visualiser graphiquement les traces LTTng).
- babeltrace : Nous pouvons voir le rapport LTTng dans la console.
Tracer l'applicatif avec LTTng
Tracer des scripts Python
- Attacher un point de trace LTTng à un programme python : les sources de l'exemple sont disponibles sur : https://github.com/jugurthab/Linux_kernel_debug/tree/master/debug-examples/Chap3-tracers/Lttng-examples/Tracing-Userspace-Python-App
- Création d'une session LTTng :
$ lttng create - Choisir le domaine à tracer : Nous devons indiquer à LTTng qu'il devra tracer une application Python comme ceci :
$ lttng enable-event --python logger-lttng - Lancer la trace :
$ lttng start - Lancer le script python : On va lancer le programme python en utilisant l'interpréteur Python3.
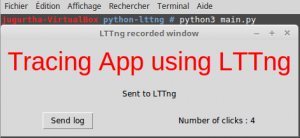
- Arrêter la trace : Une fois que le programme python est fermé, nous devons arrêter l'enregistrement
$ lttng stop - Visualiser le rapport Lttng : Enfin, nous pouvons voir le rapport associé aux clics sur le bouton.
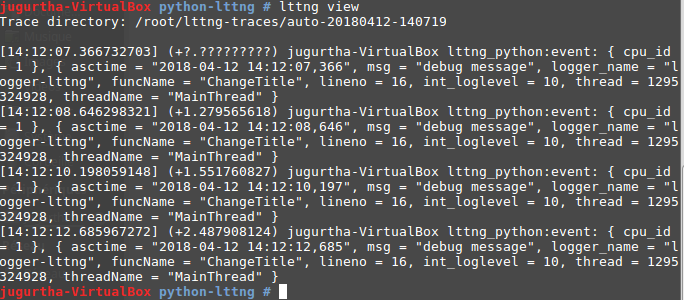
La trace peut être interprété comme suit :
[Timestamp] (Temps écoulé depuis la dernière entrée) nom_de_la_machine nom_evenement_LTTng:event: {détail sur le message}
- Création d'une session : Chaque trace produite par LTTng doit être faite dans une session.

-
Tracer du code C/C++
Nous pouvons attacher des points de trace aux applications C/C ++ en utilisant LTTng (quelque chose que nous ne pouvons pas faire avec Ftrace ou Perf).
Créer un fournisseur de tracepoint
La première étape consiste à créer un fournisseur de point de trace qui est la sonde (tracepoint) à attacher à un programme.
- directory-explorer-tracepoint.h (Fichier Header du fournisseur de points de traces) :
L'en-tête du fournisseur est définit comme modèle par LTTng. Dans l'exemple suivant, nous pouvons créer un point de trace à déclencher sur chaque découverte de fichier dans un répertoire comme suit :
- directory-explorer-tracepoint.h (Fichier Header du fournisseur de points de traces) :
#undef TRACEPOINT_PROVIDER #define TRACEPOINT_PROVIDER smile_directory_explorer_lttng_provider #undef TRACEPOINT_INCLUDE #define TRACEPOINT_INCLUDE "./directory-explorer-tracepoint.h" #if !defined(_DIRECTORY_EXPLORER_TRACEPOINT) || defined(TRACEPOINT_HEADER_MULTI_READ) #define _DIRECTORY_EXPLORER_TRACEPOINT #include <lttng/tracepoint.h> TRACEPOINT_EVENT( smile_directory_explorer_lttng_provider, //provider name defined above with TRACEPOINT_PROVIDER smile_first_tracepoint, // Tracepoint name TP_ARGS( // Tracepoint's parameters int, smile_file_number, // 1st parameter is an integer char*, smile_file_name // 2nd parameter is a string ), TP_FIELDS( ctf_integer(int, smile_file_number_label, smile_file_number) ctf_string(smile_file_name_label, smile_file_name) ) ) #endif /* _DIRECTORY_EXPLORER_TRACEPOINT */ #include <lttng/tracepoint-event.h>'
les sources sont disponibles sur ce lien : https://github.com/jugurthab/Linux_kernel_debug/tree/master/debug-examples/Chap3-tracers/Lttng-examples/Tracing-Userspace-C-App
-
- directory-explorer-tracepoint.c (Fichier source du fournisseur de points de traces) : ce fichier doit inclure le fichier d'en-tête comme indiqué ci-dessous :
#define TRACEPOINT_CREATE_PROBES #define TRACEPOINT_DEFINE #include "directory-explorer-tracepoint.h"
- Compiler le fournisseur de tracepoint :
$ gcc -c -I. directory-explorer-tracepoint.c
Exemple de code C/C++
Le code suivant permet de lister le contenu d'un dossier et d'émettre un événement LTTng lorsqu'une nouvelle entité (fichier ou dossier) est découverte.
#include <stdio.h> #include <stdlib.h> #include <dirent.h> #include <sys/types.h> #include "directory-explorer-tracepoint.h" void displayErrorMsgExit(char msg[]); int main(int argc, char *argv[]){ // used to point to a directory to discover DIR* directoryToExplore = NULL; // count nb of entities (files and folders) in a directory int Filecounter = 0; // used to point to an entity (file and folder) struct dirent* exploreredEntity = NULL; if(argc!=2){ // check nb of arguments displayErrorMsgExit("usage : ./directory-explorer PATH_TO_DIRECTORY\n"); } // Waits, because user must start LTTng before going further getchar(); directoryToExplore = opendir(argv[1]); // Open directory if(directoryToExplore==NULL){ displayErrorMsgExit("usage : ./directory-explorer PATH_TO_DIRECTORY\n"); } // Traverse directory content while((exploreredEntity = readdir(directoryToExplore)) != NULL){ Filecounter++; // Print directory entity (file and folder) printf("+ File N°: %d =====> '%s' \n", Filecounter, exploreredEntity->d_name); /* ------------------------------------------- ------- Generate an LTTng event ----------- ---- WARNING: LTTNG MUST BE STARTED ------- ---------- BEFORE THIS STEP, -------------- --- OTHERWISE EVENTS WILL NOT BE CAUGHT --- ------------------------------------------- */ tracepoint(smile_directory_explorer_lttng_provider, smile_first_tracepoint, Filecounter, exploreredEntity->d_name); } // Always close directory to free ressources if(closedir(directoryToExplore) == -1) perror("closedir Error "); return EXIT_SUCCESS; } // Display error messages void displayErrorMsgExit(char msg[]){ printf("%s\n",msg); exit(EXIT_FAILURE); }
- Compiler le code : Il faut générer un fichier objet du programme de découverte de fichier :
- Compilation du programme directory-explorer.c :
$ gcc -c directory-explorer.c - Lier le fichier object "directory-explorateur" avec le fournisseur de tracepoint :
$ gcc -o directory-explorer directory-explorer.o directory-explorer-tracepoint.o -llttng-ust -ldl
- Compilation du programme directory-explorer.c :
Tracer avec LTTng
Maintenant, on peut traçer les événements générés par l'application en utilisant LTTng.
- Lancer le programme :
$ ./directory-explorer . - Obtenir une trace avec LTTng :
- Lancer le service LTTng :
$ lttng-sessiond --daemonize - Lister les points de probes utilisateurs : Vérifiez si LTTng reconnaît le point de trace :
$ lttng list --userspaceNe pas oublier de lancer le programme de découverte (./directory-explorer, cité ci-dessus) de fichier, sinon, LTTng ne détectera pas le point de trace
- Créer une session LTTng :
$ lttng create smile-folder-explorer-tracingLTTng indiquera l'emplacement de la session de traçage (Nous en avons besoin à la fin lors de l'analyse des traces qui en résultent)
- Démarrer LTTng
$ lttng startUne fois LTTng démarré, nous pouvons revenir à notre programme et continuer son exécution
- Arrêter LTTng :
$ lttng stop
- Lancer le service LTTng :
- Lire les traçes : Nous pouvons lire les traces en utilisant Trace Compass, mais nous pouvons utiliser babeltrace (comme nous avons seulement enregistré quelques informations).
Un fichier spécial
LTTng crée un fichier spécial dans la hiérarchie ProcFs pour permettre à n'importe quelle application d'écrire des données et de générer des événements LTTng. Ce fichier s'appelle:
/proc/lttng-logger
Les scripts bash
- hello-world-smile.sh : un script qui contient un simple "echo" sur le fichier /proc/lttng-logger :
#!/bin/bash
echo 'Hello SMILE!' > /proc/lttng-logger - Ajouter les droits d'execution : par défaut, on ne peut pas exécuter les scripts (pour des raisons de sécurité) :
$ sudo chmod 777 hello-world-smile.sh - Configuration de LTTng : (voir l'image ci-dessous)
$ lttng create
$ lttng enable-event --kernel lttng_logger - Lancer la trace : Commençons l'enregistrement avec LTTng, lancons le fichier de script et arrêtons le traçage
$ lttng start
$ ./hello-world-smile.sh - Lire la trace : On peut visualiser la trace qui contient nos événements.

Encore du Code C
- write-to-lttng-log.c : un autre exemple avec du code C :
int main(){ FILE* fd_writer_to_log = NULL; // open LTTng special file fd_writer_to_log = fopen("/proc/lttng-logger","r+"); if (fd_writer_to_log != NULL) { // Write a string to file fprintf(fd_writer_to_log,"""Hello SMILE from C Code!\n"); fclose(fd_writer_to_log); } else { printf("Cannot open /proc/lttng-logger\n"); exit(EXIT_FAILURE); } return EXIT_SUCCESS; }
Note : Le fichier lttng-logger existe seulement quand LTTng est lancé.
- Configurer LTTng : il faut paramétrer LTTng afin d’écrire dans le "/proc/lttng-logger" :
$ lttng create
$ lttng enable-event --kernel lttng_logger - Lancer la trace :
$ lttng start
$ ./write-to-lttng-log - Lire la trace : Nous pouvons jeter un coup d'oeil sur les traces :

LTTng est plus simple avec "LTTng toolkit analyses"
LTTng fournit une puissante boîte à outils appelée "analyses toolkit LTTng" pour extraire les données les plus pertinentes des traces enregistrées.
le kit LTTng analyses
Cette suite d'outils est accessible sur : https://github.com/lttng/lttng-analyses
Enregistrement des traces LTTng
- Enregistrement automatique de session (recommandé) : LTTng toolkit analyses est livré avec un script qui enregistre automatiquement une session complète (plus besoin d'une configuration fastidieuse). Cette méthode est assez efficace en production.
$ sudo lttng-analyses-record
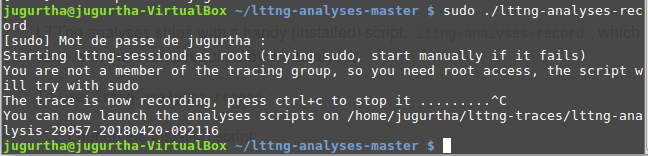
- Enregistrement manuel de session : Il est également possible d'enregistrer manuellement une session comme nous l'avons déjà fait jusqu'à présent.
Le kit LTTng analyses
Une fois qu'une trace a été obtenue avec LTTng, on peut extraire ses données avec LTTng analyses toolkit de diverses façons. Nous pouvons simplement afficher des statistiques, ou encore utiliser des outils dédiés à l'analyse de problèmes liés au entrées / sorties, aux interruptions, à l'ordonnanceur.
Statistiques
Cet outil affiche les statistiques d'utilisation liées aux processeurs.
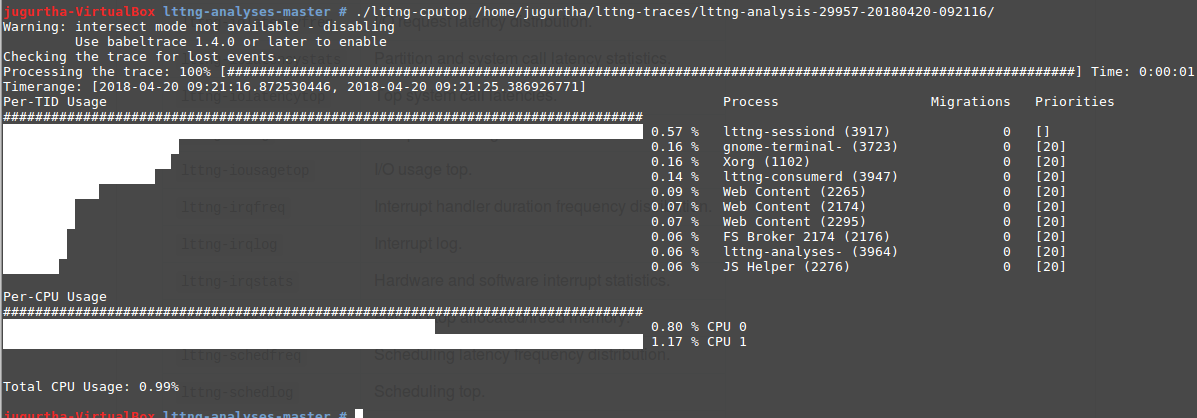
La sortie est divisée en 3 parties :
Per-TID Usage : Temps CPU utilisé par chaque processus présent au moment du traçage trié par consommation.
Per-CPU Usage : Fournit la charge de travail moyenne sur chaque CPU, dans notre exemple, nous avons 2 processeurs qui ne dépassent pas 1,17% d'utilisation
Total CPU Usage : utilisation totale du temps des processeurs (généralement c'est la somme de la charge de travail sur chaque CPU / nombre de CPU)
les scripts I/O
Les problèmes I/O sont courants dans différents systèmes, être capable de les démasquer rapidement est une compétence cruciale.
"LTTng analyses toolkit" contient des outils très précieux pour chaque développeur Linux ou ingénieur de performance, tels que :
- lttng-iolatencystats : Liste des appels système I/O effectués au moment de l'enregistrement de la trace.

- lttng-iolatencytop : Affiche les latences I/O dans l'ordre décroissant.
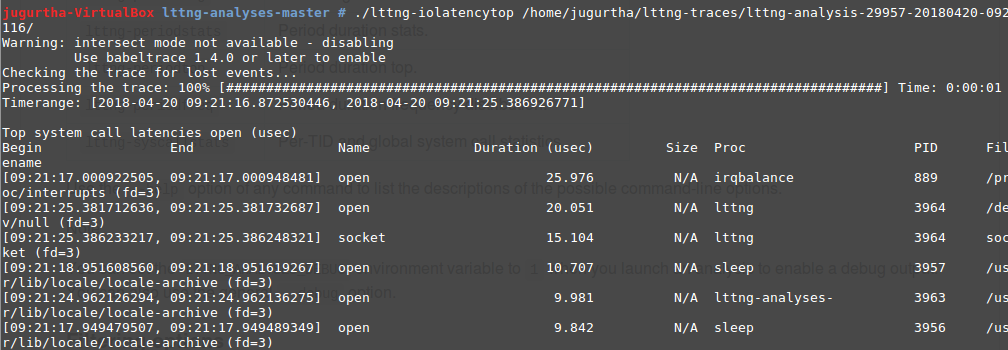
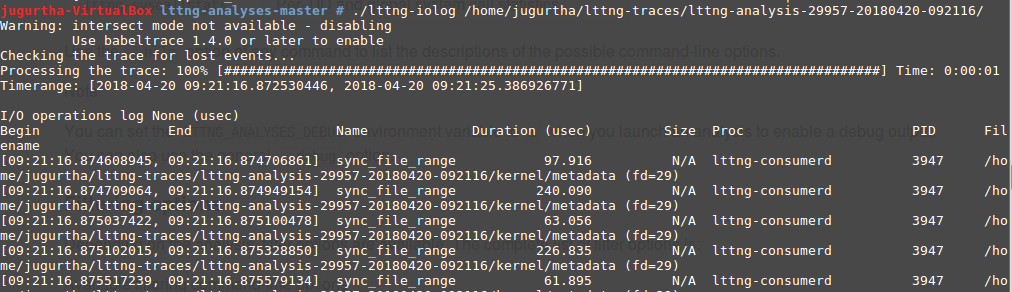
- lttng-iolog : Retourne la chronologie I/O dans le système au moment du traçage :
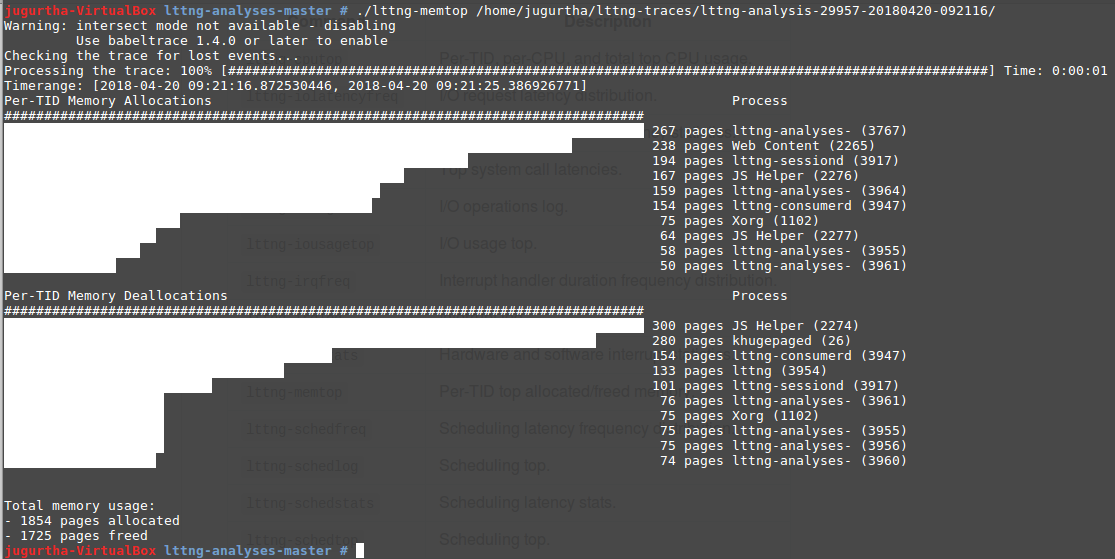
- lttng-memtop : Affiche les statistiques globales de la mémoire.
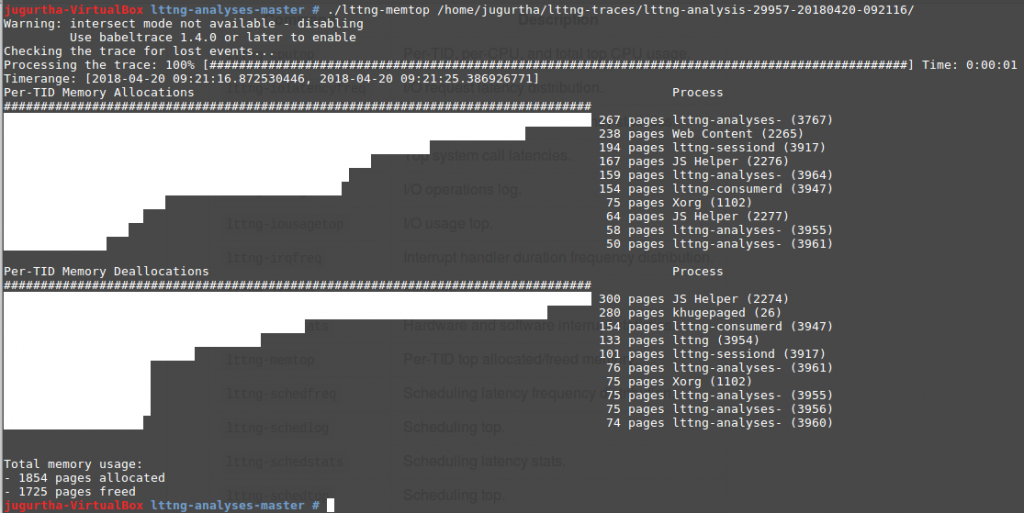
- Per-TID Memory Allocations : Nombre de pages allouées par chaque processus (triées par ordre décroissant du nombre de pages).
- Per-TID Memory Deallocations : Nombre de pages désallouées par chaque processus (triées par ordre décroissant de nombre de pages).
- Total memory usage : C'est la somme de toutes les pages allouées et désallouées.
Les interruptions
Les interruptions peuvent être la source de latences, c'est aussi un problème commun que nous voyons en pratique. Heureusement, avec LTTng analyses, nous pouvons être efficaces pour y faire face.
- lttng-irqstats : visualiser les interruptions logicielles et matérielles enregistrées pendant la période de traçage :

- lttng-irqfreq : affiche la fréquence de distribution de la durée de chaque interruption.
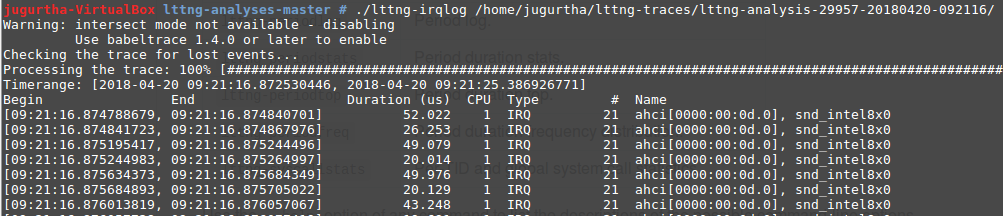
- lttng-irqlog : affiche la chronologie des interruptions qui ont eu lieu depuis le début jusqu'à la fin du traçage.
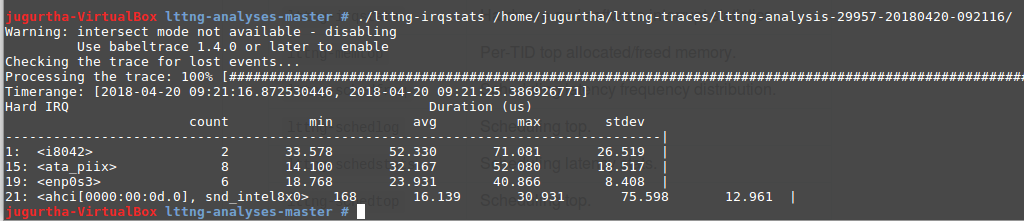
L'ordonnanceur
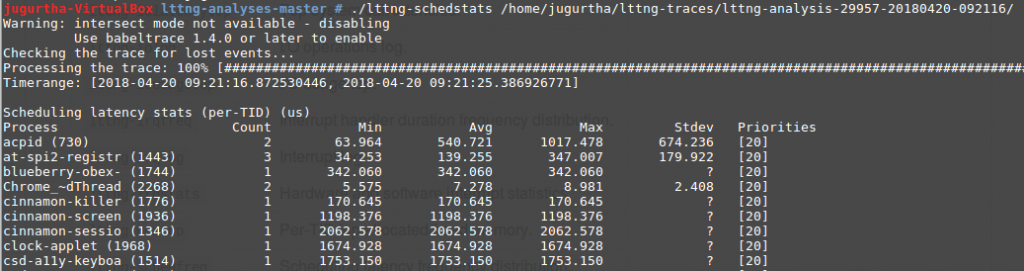
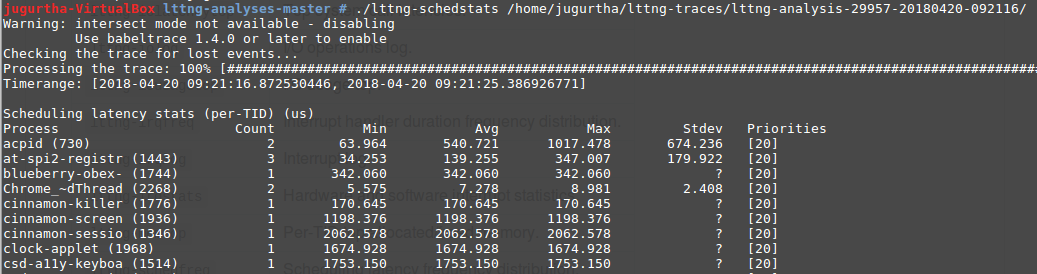
- lttng-schedstats : affiche diverses informations associées à l'ordonnancement de chaque tâche :
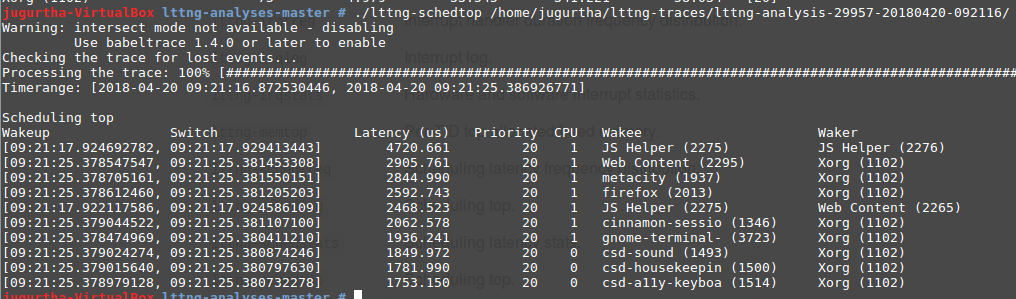
- lttng-schedtop : Affiche les latences de l'ordonnancement les plus élevées triées par ordre décroissant.
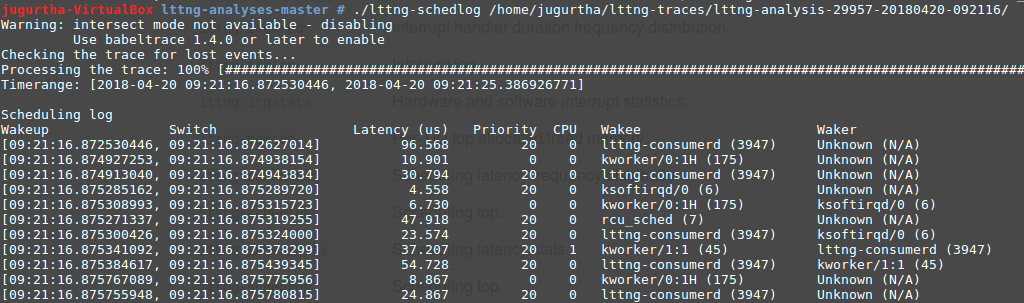
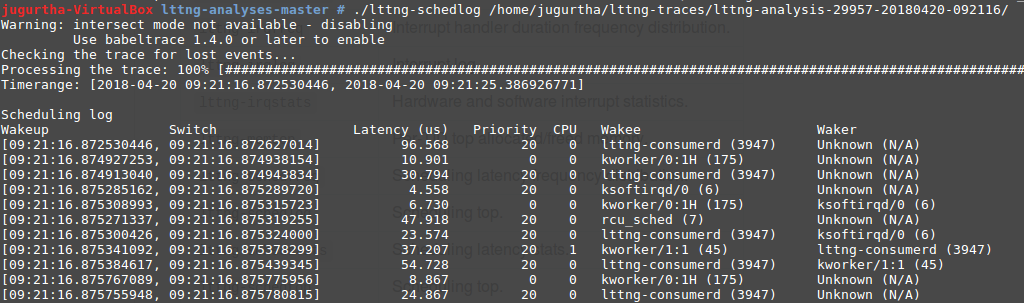
- lttng-schedlog : on peut obtenir une meilleur perception de la latence en regardant la chronologie du journal de l'ordonnancement.
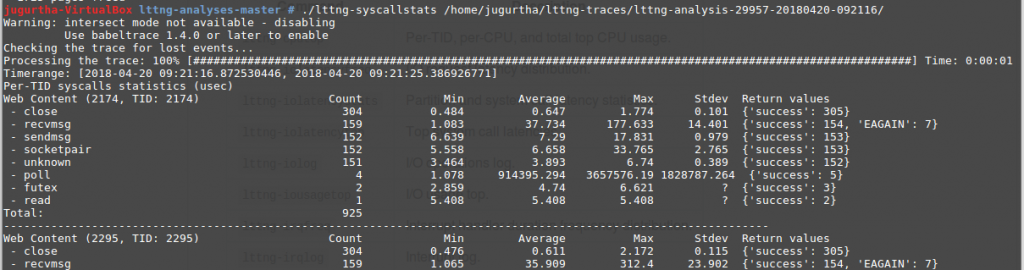
- lttng-syscallstats : Permet de lister tous les appels système effectués par tous les processus présents dans le système au moment du traçage.
Choisir un traceur
Le tableau suivant résume les grands points qu'il faut retenir sur les traceurs que nous avons présentés :
| Outils | Support natif | Outils Front-end | Traçage réseau | Parsseurs GUI |
|---|---|---|---|---|
| Ftrace | depuis linux 2.7 | Trace-cmd | Oui | KernelShark |
| Perf_event | depuis linux 2.8 | Perf | Non | Hotspot |
| LTTng | Non | LTTng | Oui | Trace compass |
Pour mieux comprendre la différence entre ces traceurs, nous allons essayer de les comparer avec un benchmark.
Critères de selection
Intrusivité mémoire
- VSS (Virtual Set Size) : somme totale de la mémoire mappée dans l'espace virtuelle.
Plus précisément, Vss est la somme de toutes les entrées dans /proc/pid/mapsCe paramètre est inutile pour nous car un processus peut prendre autant de mémoire virtuelle qu'il souhaite , seule une partie de celui-ci sera mappée à la mémoire physique.
- RSS (Resident Set Size) : nombre total de pages mappées en mémoire. Cependant, cela tient également compte des bibliothèques partagées.
Rss agrège le nombre de pages appartenant à un processus + pages partagéesNous allons utiliser cette métrique car elle peut être obtenue facilement à partir d'outils intégrés
Encore plus de métrique mémoire
En 2009, Matt Mackall a apporté de nouvelles mesures comme suit :
- Uss (Unique set size) : somme des pages qui n'appartiennent qu'à un processus spécifique (propore à un processus)
- Pss (Proportional set size) : ce paramètre est un peu plus complexe :
Pss = pages privées à un processus donné + (nombre de pages partagées / nombre de processus qui les partagent)
Exemple : si 3 processus partagent 21 pages, alors (21/3 = 7 pages) sera ajouté au Pss de chaque.
Intrusivité temps d’exécution
- Temps d'exécution avec/sans le traceur : Nous allons comparer les deux cas.
- Chagement de contexte : les changements de contexte sont connus pour ralentir l'exécution car nous devons continuellement entrer et sortir du noyau (en utilisant les appels système).
Plus de changements de contexte = plus de latence d'exécution
Divers
- Architectures supportées : La plupart du temps, les traceurs supportent l'architecture x86 (car ils sont principalement conçus pour les ordinateurs de bureau et les serveurs) mais pour les systèmes embarqués, un tel paramètre doit être pris en compte
- Rapport en temps réél : Une autre métrique importante est la possibilité de surveiller les événements en temps réel (ou est-il toujours nécessaire de produire un fichier de trace pour le post-traitement?).
- Taille du rapport : Les systèmes embarqués ont peu d'espace de stockage, il est important de garder le fichier aussi petit que possible.
Outils de vérification des critères
Nous avons besoin d'outils permettant d'obtenir une mesure précise des critères ci-dessus, jetons un coup d'œil à certains d'entre eux :
l'utilitaire time
Il suffit de lancer cette commande sur un programme :
$ time ./monProgram
L'outil renvoie 3 valeurs :
- real : temps d'exécution écoulé depuis le début jusqu'à la fin.
- user : temps d'exécution du processeur en mode utilisateur.
- sys : Temps d'exécution du processeur en mode noyau.

l'utilitaire /usr/bin/time
La commande doit êtree lancé comme suit :
$ /usr/bin/time ./monProgram
Cette commande renvoie plusieurs valeurs, nous verrons celles qui nous intéressent le plus :
- Maximum resident set size : donne la valeur Rss la plus défavorable (la plus élevé) du début à la fin du programme.
- Voluntary context switches : un processus (ou un thread) libère explicitement le processeur.
- Involuntary context switches : un processus (ou thread) est obligé de libérer le processeur pour diverses raisons (timelice épuisé, préempté par un processus prioritaire, attente d'une ressource, ..., etc).
Un simple benchmark
Ayant les bons critères et outils, nous avons besoin d'un programme sur lequel tester. Nous pouvons choisir un algorithme de tri et l'un d'entre eux est déjà disponible sur Linux, c'est "qsort".
qsort est une fonction fournie par la bibliothèque C.
Code "qsort" complet
#include <stdio.h> #include <stdlib.h> #include <time.h> #define MAX_NUMBER 36000 #define ARRAY_SIZE 1000000 int cmpfunc (const void * a, const void * b) { return ( *(int*)a - *(int*)b ); } int main () { int n=0; srand(time(NULL)); // should only be called once int i, a[ARRAY_SIZE] = {0}; for(i = 0; i < ARRAY_SIZE; ++i) a[i] = rand() % MAX_NUMBER; qsort(a, ARRAY_SIZE, sizeof(int), cmpfunc); return(0); }
Benchmarking
Nous avons codé un petit utilitaire qui nous aidera à utiliser le progamme (/usr/bin/time) et faire un benchmark plusieurs fois avec/sans traceur avec l'algorithme qsort.
Les sources du benchmark
Le benchmarker (ftrace-perf-lttng-benchmarker) est disponible sur ce lien : https://github.com/jugurthab/Linux_kernel_debug/tree/master/DebugSoftware/tracers-cmp-benchmark
Compiler les sources
$ gcc -o qsort qsort.cpp
$ gcc -o ftrace-perf-lttng-benchmarker ftrace-perf-lttng-benchmarker.c
Après avoir compilé les sources, le benchmarker peut s'utiliser de la manière suivante :
$ sudo ./ftrace-perf-lttng-benchmarker [select-tracer] [number_of_tests_to_perform]
- select-tracer : 1 - ftrace, 2 - Perf, 3 - LTTng, 4 - tout les traceurs
- number_of_tests_to_perform : nombre de fois à répéter la collecte des données. Il est toujours préférable de prendre la moyenne de plusieurs tests.
Par exemple : pour faire un benchmark de tous traceurs en répétant le test pendant 10 fois :
$ sudo ./ftrace-perf-lttng-benchmarker 4 10
à la fin du benchmark, le programme va créer un dossier "output-trace-cmp" dans lequel sont stockés les résultats des tests.
Visualiser les résultats du benchmark
Nous devons à présent parser le résultat des tests, pour cela nous allons utiliser un autre programme CMPTracers-GUI.
CMPTracers-GUI
Les sources sont disponible sur ce lien : https://github.com/jugurthab/Linux_kernel_debug/tree/master/DebugSoftware/cmpTracer-GUI
Remarque : CMPTracer-GUI doit être utilisé sur une machine Desktop, il sert a parser les résultats (le dossier output-trace-cmp) produit par ftrace-perf-lttng-benchmarker.
- Lancer CMPTracer-GUI :
$ sudo apt-get install python3
$ sudo apt-get install python3-tk
$ sudo python3 main.py
On devra voir la fenêtre suivante :
- Sélectionner le dossier output : choisir le chemin du dossier "output-trace-cmp" :
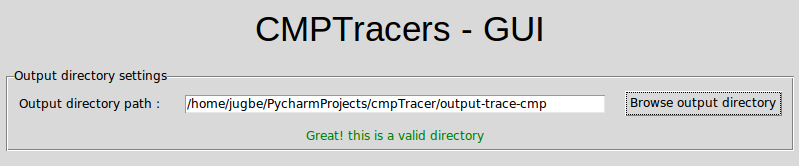
- Information lu par CMPTracer-GUI :
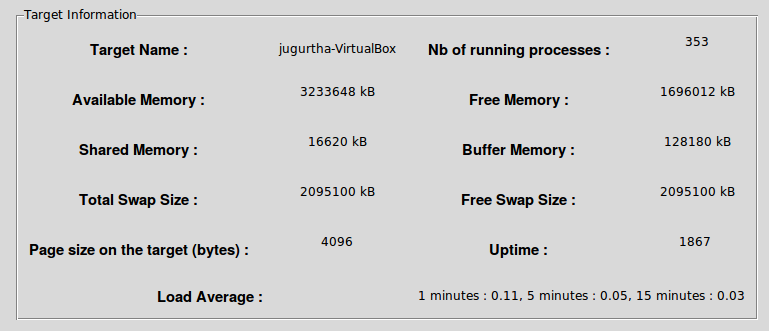
- Information sur la trace : CMPTracer-GUI récupère le nombre de tests et les traceurs qui ont été sélectionnés pour l’expérimentation.

- Etat de la machine avant l'expérimentation : Il est aussi important de connaître l’état initial de la machine avant l'expérience (ces données sont enregistrées par "ftrace-perf-lttng-benchmarker" avant de commencer le benchmarking).
- Résultat de l'expérience : Les boutons de contrôles permettent de visualiser les différences entre les différent traceurs, cela permet d'obtenir les résultats suivants :
Outils Temps d'exécution (s) RSS maximum (KB) Changement contexte volontaire Changement contexte involontaire défaut de pages taille de la trace (KB) qsort sans traceur 0.19 8818 1 79 1194 0 qsort avec Ftrace 4.04 8848 170 261 1323 29418 qsort avec Perf 0.53 10227 27 118 3170 23 qsort avec LTTng 0.21 8834 1 69 1213 2723
- Information sur la trace : CMPTracer-GUI récupère le nombre de tests et les traceurs qui ont été sélectionnés pour l’expérimentation.
Conclusion
Nous avons découvert au cours de cet article les traceurs Linux (Perf et LTTng) et leur utilisation à partir de zéro. Nous avons également conduit un benchmark pour nous aider à sélectionner l'outil le plus approprié.
Il reste encore des choses à voir qui ne sont pas abordés dans cet article : https://github.com/jugurthab/Linux_kernel_debug/blob/master/debugging-linux-kernel.pdf
Pour aller encore plus loin, le blog de Brendan Gregg est une excellente référence.