La gestion de l'énergie sur un système informatique est l'une des préoccupations principales de ces dernières années. Tous les domaines de l'informatique sont concernés, allant des systèmes embarqués très basse consommation jusqu'aux fermes de serveurs en passant par les PC de bureau et les ordinateurs portables.
Lorsque l'on cherche à gérer l'énergie depuis la couche logicielle, tout devient affaire de compromis. Chaque action entreprise pour économiser de l'énergie va avoir des répercussions sur les performances du système. A l'inverse, optimiser les performances, ou imposer des contraintes de latence va souvent se faire au détriment de la consommation énergétique.
Les systèmes nécessitant du temps-réel sous Linux vont devoir tenir compte de leurs paramètres de power-management pour éviter de mauvaises surprises liées aux endormissements intempestifs de leur périphériques.
Cet article abordera les différents frameworks et sous-systèmes proposés par le noyau Linux pour piloter la consommation énergétique d'un système, du côté noyau et espace utilisateur, en mettant le doigt sur les problématiques associées à chaque sous-système.
Enjeux
Beaucoup de constructeurs de matériels implémentent des modes avancés de power-management dans leurs produits. Les frameworks du noyau ont pour rôle de mettre à disposition des mécanismes permettant à la fois de supporter au mieux ces modes, mais aussi de proposer une interface générique à l'utilisateur et aux développeurs de drivers.
Étant donné la proximité avec le matériel, les frameworks de power-management sont pour la plupart légers, avec une interface très simple, laissant beaucoup de liberté au développeurs de drivers pour implémenter les mécanismes spécifiques à chaque matériel.
Par ailleurs, les sous-systèmes liés au power-management restent au maximum transparents pour l'utilisateur. En ce qui concerne le power-management dynamique, l'espace utilisateur va simplement pouvoir donner les "grandes lignes" de la politique de power-management, en indiquant au noyau de privilégier soit les performances et faibles latences, soit l'économie d'énergie.
Nous constaterons cependant que plus les techniques mises en place pour le power-management sont agressives, plus l'utilisateur devra intervenir pour les utiliser. Ainsi, les entrées en modes d'endormissement ne se font que sur ordre de l'espace utilisateur.
Power-management dynamique
Le power-management dynamique regroupe toutes les techniques permettant de contrôler la consommation énergétique pendant que le système est actif et que les processus en espace utilisateur tournent. Il s'agit d'être transparent pour l'espace utilisateur tout en lui laissant la possibilité de spécifier ses contraintes.
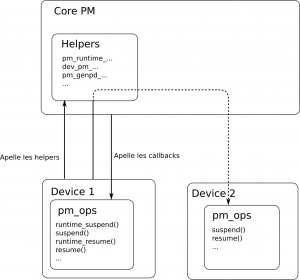
Le power-management dynamique est une partie du sous-système de power-management de Linux, appelé le 'PM core'. Le PM core s'interface avec le reste des sous-systèmes et drivers par l'intermédiaire de callbacks, appelées par le core PM, et de fonctions dites "helper" implémentées par le core PM et appelées par les drivers et sous-systèmes.
Les callbacks sont le plus souvent stockées dans le sous-systèmes au sein d'une structure dédiée, souvent appelée `pm_ops`. Toutes les mentions aux `pm_ops` dans la suite de cet article feront référence aux callbacks de power-management.
On retrouve principalement ces `pm_ops` dans les drivers de périphériques, lorsque ceux-ci permettent d'économiser de l'énergie par rapport à leur fonctionnement nominal. On les retrouve aussi dans les drivers de bus, ou encore dans les pilotes génériques implémentant des protocoles et systèmes de fichiers. De cette manière, la plupart des composants du noyau peuvent être informés des différentes mesures de power-management appliquées et réagir en conséquence.
runtime_pm
Le framework runtime_pm est la partie du PM core dédiée au power-management dynamique.
Ce framework permet à différents sous-systèmes et drivers du noyau de définir un ensemble de callbacks, préfixées par 'runtime_', qui seront appelées par le noyau lorsque nécessaire.
Lorsque le périphérique n'est plus utilisé par aucun composant du système, celui-ci peut alors être mis dans un mode dit "suspended", dans lequel il est garanti que le driver ne sera pas utilisé avant la sortie de ce mode (callback runtime_resume).
La détection de l'utilisation d'un périphérique se fait par comptage de références, ainsi que par la gestion de la hiérarchie.
L'interface étant relativement simple, nous pouvons nous attarder sur les 3 principales callbacks proposées par le framework :
/** * Cette callback est appelée lorsque le sous-système PM décide que le * périphérique n'est plus activement utilisé. Si cet appel retourne avec * succès, le périphérique ne doit plus interagir avec le système tant que la * callback runtime_resume n'a pas été appelée. */ int runtime_suspend(struct device *dev) /** * Cette callback est appelée lorsque le système veut accéder à ce périphérique * alors qu'il est 'suspended'. Le périphérique doit retourner dans un état * fonctionnel après cet appel. */ int runtime_resume(struct device *dev) /** * Cette callback est appelée lorsque le périphérique n'est plus utilisé, en se * basant sur le compteur d'utilisations du périphérique, ainsi que sur le nombre * d'enfants actifs. L'action effectuée par cette callback est entièrement définie * par le driver, dans la plupart des cas il s'agit d'un appel à runtime_suspend. */ int runtime_idle(struct device *dev)
Certains drivers enregistrent également des timers d'autosuspend, qui vont déclencher l'appel de la callback 'runtime_suspend' si aucune activité n'est détectée sur ce périphérique avant l'expiration du timer.
Domaines
Un domaine de power management (PM domain) représente un ensemble de sous-systèmes alimentés par les mêmes tensions et horloges. Ainsi, lorsque tous les périphériques liés à un domaine sont inutilisés, il peut être intéressant de changer les fréquences et tensions afin d'économiser davantage d'énergie.
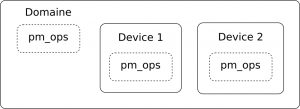
Ce genre de "cluster" de sous-systèmes se retrouve surtout sur les SoC, où ils peuvent être assez complexes, avec des relations de parent-enfant. Le framework PM Core inclut la gestion des domaines et des sous-domaines, et tient compte des informations remontées par le framework QoS.
Dans la plupart des cas, les domaines sont décrits directement dans le device-tree grâce à un binding prévu à cet effet.
Les domaines sont gérés par le noyau grâce à un sous-système dédié dans le PM core, qui va suivre l'état des différents périphériques liés à ce domaine et potentiellement couper l'alimentation des horloges du domaine lorsque tous les périphériques sont "suspended".
cpuidle
L'un des composants les plus gourmands d'un système est paradoxalement celui qui passe la plus grande partie de son temps à ne rien faire : le CPU. Le CPU est particulier, car il est très souvent sollicité pour de courtes périodes. Il est rare de trouver un système sur lequel le CPU est en permanence sollicité 100% du temps. Plusieurs fois par seconde, il va devoir être pleinement opérationnel pour exécuter les programmes qui ont besoin de tourner, puis se rendormir dans un état de sommeil léger, dit "Idle", caractérisé par un arrêt de l’exécution des instructions, une plus faible consommation, mais aussi une latence de sortie plus ou moins grande avant de revenir à un état fonctionnel.
Modes Idle d'un CPU
Les CPUs modernes possèdent plusieurs modes idle, quelques-uns pour les cœurs ARM, jusqu'à une dizaine pour certains x86. Chaque mode est caractérisé par 3 attributs :
- Le temps de latence pour sortir du mode
- La puissance consommée dans ce mode
- Le temps à partir duquel il est "rentable" d'utiliser ce mode
Un mode est souvent appelé "C-state", en référence au nom de ces états dans la norme ACPI. Le mode nominal du CPU lorsqu'il est pleinement opérationnel est l'état C0. Les états vont alors en s'incrémentant, chaque état éteignant davantage de composants internes du CPU, pour de plus grandes économies d'énergie mais une plus grande latence de réveil.
Pour exemple, voici la liste des C-states supportés par Linux pour un Intel i5-5300U, avec leurs latences de réveil respectives :
- POLL : 0µs ( Cet état est une simple boucle d'attente )
- C1 : 2µs
- C1E : 10µs
- C3 : 40µs
- C6 : 133µs
- C7s : 166µs
- C8 : 300µs
- C9 : 600µs
- C10 : 2600µs
Sur plateformes ARM, on ne retrouve en général qu'un ou deux C-states. Par défaut, ARM propose l'état WFI (Wait For Interrupt), qui va mettre le CPU en état low-power et couper certaines horloges jusqu'à la prochaine interruption, comme expliqué sur ce document édité par ARM. Certains SoCs ARM implémentent d'autres états supplémentaires, comme les exynos de Samsung.
L'outil `powertop` permet de consulter les C-states supportés par chaque cœur, package et socket de votre CPU. Vous pourrez y trouver le pourcentage de temps passé dans chaque état.
Il est possible de consulter les C-states de votre CPU supportés par votre système en parcourant l'interface sysfs du framework cpuidle :
# Chaque répertoire dans /sys/devices/system/cpu/cpuX/cpuidle/ correspond à un # C-state supporté pour ce CPU. :~$ ls /sys/devices/system/cpu/cpu0/cpuidle/ state0 state1 state2 state3 state4 state5 state6 state7 state8 # Dans chaque répertoire, les informations suivantes peuvent être trouvées : ls /sys/devices/system/cpu/cpu0/cpuidle/state0/ desc disable latency name power residency time usage
Parmi les attributs relatifs à un C-state, on retrouve :
- desc : une courte description de l'état.
- name : le nom de l'état.
- power : la puissance en mW consommée dans cet état. Les valeurs indiquées sont cependant peu fiables, le plus souvent des 0 ou INT_MAX.
- latency : le temps nécessaire pour se réveiller depuis cet état, en microsecondes.
- residency : le temps estimé d'endormissement à partir duquel il devient intéressant d'utiliser cet état.
Cpuidle et ses governors
Le concept de "governor" se retrouve dans plusieurs sous-systèmes du noyau. Il s'agit d'un composant logiciel modulaire qui implémente un algorithme devant faire un choix entre plusieurs états, implémentés dans des drivers d'états. Le fait d'utiliser un composant modulaire permet de changer de governor à la volée, ce qui est utile pour le cas de cpuidle, car le governor implémente l'algorithme qui se charge de choisir le C-state dans lequel entrer.
Lorsque le scheduler n'a plus de tâche à exécuter sur un CPU, il va demander au framework cpuidle de mettre le CPU en état d'endormissement. Cpuidle va alors demander au governor actuel de choisir l'état cible en appelant la callback `select()`. La callback `enter()` de l'état choisi est ensuite appelée, mais rien ne garantit que c'est réellement cet état qui sera appliqué. En effet, le CPU lui-même peut avoir accès à d'autres heuristiques implémentées matériellement et choisir un autre état.
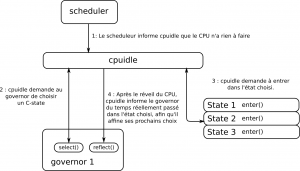
Afin de choisir pertinemment un C-state, il est important d'avoir une estimation fiable du temps durant lequel le CPU va rester idle. Il est assez simple d'estimer le temps avant le prochain timer tick (les évènements de scheduling), il est en revanche beaucoup plus difficile d'estimer quand arriveront des interruptions externes.
C'est pourquoi après que le CPU ait effectué son temps en idle, le framework cpuidle va appeler la callback `reflect()` du governor avec en paramètre le temps réel passé endormi, afin que le governor puisse ajuster ses heuristiques et tenir compte des conditions actuelles du système, par exemple en détectant que beaucoup d'interruptions sont actuellement levées.
Tension dynamique et réglage de fréquence
Nous avons vu que le sous-système cpuidle contrôle l'état du CPU lorsqu'il ne fait rien. Il existe également le sous-système cpufreq qui contrôle l'état du CPU lorsqu'il exécute quelque chose. En particulier, il convient de régler la bonne fréquence (frequency scaling) et d'adapter dynamiquement la tension d'alimentation (dynamic voltage) afin que le CPU puisse effectuer toutes ses tâches, tout en réduisant l'énergie consommée.
Cela peut aussi s'appliquer à d'autres périphériques, tels que la RAM, le GPU et de manière générale, tout ce qui est piloté par des tensions et fréquences que l'on peut contrôler depuis l'OS.
Points de Performance Opérationnelle
Les Operating Performance Points (OPP) sont des tuples [fréquence,tension] permettant de représenter les différents paramètres acceptés par les périphériques.
En effet, la fréquence d'une horloge ne se contrôle pas de manière continue et changer la fréquence de fonctionnement implique le plus souvent de changer la tension d'alimentation du composant.
Les OPP permettent une représentation générique de ces points au sein du noyau, peuvent être ajoutés/retirés dynamiquement et consultés par les drivers qui vont les utiliser. On trouve notamment des liaisons dans le device-tree permettant de donner une correspondance entre les points génériques du noyau et les OPP spécifique au processeur ( voir la documentation du noyau )
Cpufreq et ses governors
CPU Freq met en œuvre le DVFS pour le contrôle du CPU, en se basant sur une listed'OPP spécifique au CPU.
Certains CPU vont directement implémenter matériellement le changement d'OPP (on parle alors de P-states, selon la norme ACPI). Dans ce cas, l'OS peut simplement définir les bornes supérieures et inférieures des fréquences pouvant être utilisées par le CPU. On parle alors de 'policy'.
Le choix de l'OPP se fait en utilsant des governors, de manière similaire à cpuidle.
Linux propose plusieurs governors, plus ou moins intelligents :
- performance : ce governor choisit systématiquement l'OPP le plus élevé, afin d'avoir toujours les performances maximales.
- powersave : à l'inverse de performance, ce governor choisit toujours l'OPP le plus bas, afin d'économiser l'énergie.
- ondemand : ce governor utilise quelques heuristiques afin de réduire la fréquence lors des périodes de faible charge, mais remet la fréquence au maximum dès que nécessaire.
- conservative : le governor conservative fonctionne d'une manière similaire au governor ondemand, en s'adaptant à la charge actuelle du CPU. Il va cependant ajuster la fréquence par paliers en évitant d'utiliser subitement la fréquence maximale.
- userspace : le governor userspace laisse tout simplement l'utilisateur choisir manuellement l'OPP à utiliser lorsque le CPU est actif.
- schedutil : le governor schedutil constitue un pas de plus vers une fusion de cpufreq, cpuidle et du scheduler. En effet, schedutil est directement implémenté dans le scheduler et dispose ainsi de métriques beaucoup plus précises et pertinentes sur la charge actuelle du système.
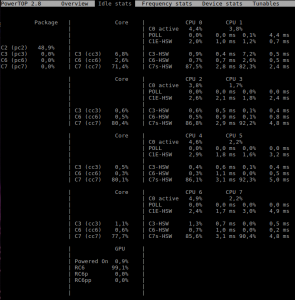
L'outil `powertop` vous permet aussi de voir à quelles fréquences vos périphériques fonctionnent et de visualiser le pourcentage d'utilisation des différents OPP :
Qualité de Service
Les techniques de PM dynamiques peuvent influer directement des composants critiques du système tels que le CPU, les fréquences de certains bus, ou encore les périphériques d'entrée/sortie. Cela peut introduire des latences inacceptables pour l'utilisateur final, mais aussi pour certains périphériques.
L'espace utilisateur, mais aussi certains drivers peuvent exprimer des contraintes de latences, de débit, ou encore interdire à certains sous-systèmes d'entrer en mode lowpower grâce au framework Quality of Service (QoS).
Classes QoS
Les classes QoS sont des paramètres globaux, pouvant être contrôlés par les drivers ainsi que par l'espace utilisateur. Ces paramètres sont pris en compte par les drivers et les frameworks liés au PM.
Parmi ces classes, on trouve :
- cpu_dma_latency (microsecondes) : permet de spécifier une latence maximale limite pour le réveil du CPU, en particulier lors de l'utilisation du DMA. Le DMA se faisant dans le dos du CPU, les frameworks cpuidle et cpufreq peuvent parfois prendre des décisions trop agressives en pensant que le CPU est inactif, alors qu'un transfert DMA est en cours. Cela peut conduire à de grosses latences lors de la notification de la fin du transfert DMA. Ce paramètre influe sur les C-states qui seront choisis par cpuidle. Plus la latence demandée est basse, moins le CPU s'endort profondément.
- memory_bandwidth (mbps)
- network_latency (microsecondes)
- network_throughput (kbps)
Plusieurs sources peuvent spécifier une valeur minimale pour chaque classe. Le framework QoS va s'occuper de calculer une valeur agrégée pour chaque paramètre qui sera la valeur cible globale. Ces valeurs ont une grande importance pour le power management, car elles vont permettre de limiter l’agressivité de l'économie d'énergie.
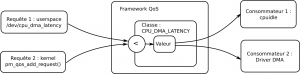
QoS par périphérique
En plus des classes, le framework QoS permet d'attacher des attributs de QoS à chaque composant. Actuellement, trois attributs sont proposés :
- resume latency : permet de spécifier une latence maximale de réveil pour ce périphérique, à l'instar de cpu_dma_latency pour le CPU.
- active state latency tolerance : certains périphériques ont un contrôle de l'énergie au niveau matériel. Lorsque ce contrôle peut être paramétré depuis la couche logicielle, un driver peut implémenter ce paramètre QoS afin de permettre à l'utilisateur d’empêcher le matériel d'être trop agressif dans son contrôle de l'énergie.
- flags : NO_POWER_OFF, REMOTE_WAKEUP : ces flags sont là pour empêcher totalement le périphérique de passer en mode "suspended" ainsi que pour contrôler et vérifier la capacité d'un périphérique à réveiller le système lors d'un endormissement.
Gestion de la température
La gestion de la consommation électrique impacte aussi l'emission de chaleur par le système. Il peut être nécessaire de limiter volontairement les performances afin de satisfaire aux contraintes de température, notamment sur un système qui refroidit passivement.
Le sous-système 'thermal' permet de gérer différents profils thermiques, qui s'activent lorsque certaines conditions de température sont rencontrées.
Chaque profil peut définir une méthode de refroidissement à utiliser lorsque la température cible est atteinte. Il peut s'agir d'activer un ventilateur, ou bien d'utiliser cpufreq pour limiter la fréquence de fonctionnement du système.
Vous pouvez consulter les différents profils thermiques avec l'interface sysfs :
:~$ find /sys/class/thermal/ /sys/class/thermal/ /sys/class/thermal/cooling_device0 /sys/class/thermal/cooling_device1 /sys/class/thermal/cooling_device2 /sys/class/thermal/cooling_device3 /sys/class/thermal/thermal_zone0 /sys/class/thermal/thermal_zone1
Un 'cooling_device' représente une instance d'un périphérique permettant d'influer sur la température du CPU. Par exemple, cette instance peut contrôler un OPP pour cpufreq, ou encore une vitesse de rotation pour un ventilateur.
Une 'thermal_zone' représente un driver de capteur de température. Chacun de ces drivers peut définir différents seuils de température. Lorsqu'un de ces derniers est atteint, une action associée dans les 'cooling_devices' peut être exécutée.
Modes d'endormissement
Les modes d'endormissement sont des techniques plus agressives de power management, car les processus en espace utilisateur ne sont plus exécutés pendant ces périodes. Un processus en espace utilisateur peut prendre la décision de faire rentrer tout le système dans un mode d'endormissement, le noyau n'as pas la possibilité de deviner quand le système va être endormi.
L'espace utilisateur doit alors configurer la source de réveil, pour indiquer quel(s) évènement(s) extérieur(s) sort l'appareil de son mode d'endormissement. Les sources de réveil sont principalement des interruptions matérielles. Cela peut être un évènement de type 'timer', l'appui sur une touche d'un clavier ou sur le bouton power, cela étant limité par les possibilités de chaque périphérique. En effet, chaque driver gérant un périphérique peut fournir une source de réveil, généralement en spécifiant que cette source correspond à une interruption qu'il prend en charge. Lorsque c'est le cas, on peut activer/désactiver la source de réveil depuis le sysfs en écrivant dans le fichier 'wakeup'.
find /sys/devices -name "wakeup"
La description des fichiers du sysfs gérant le réveil se trouve dans la documentation du noyau :
https://www.kernel.org/doc/Documentation/ABI/testing/sysfs-devices-power
Pour demander au système de s'endormir, l'utilisateur doit écrire le mode dans lequel il souhaite entrer dans le fichier '/sys/power/state'. L'appel à 'write' sera alors bloquant jusqu'au réveil du système, excepté pour le mode 'disk'.
La liste des états supportés peut être consultée en lisant ce même fichier. Les différents modes sont décrits dans la documentation du noyau.
freeze
echo freeze > /sys/power/state
Le mode 'freeze' est le mode d'endormissement le plus simple, dans le sens où il est purement logiciel et ne fait presque pas appel aux capacités matérielles de mise en lowpower. Il s'agit simplement de geler tous les processus en espace utilisateur, permettant ainsi au CPU de rester en mode idle la plupart du temps (il reste tout de même certains process actifs dans le noyau). Étant donné que cet état est très peu dépendant du matériel, il est toujours supporté.
mem
echo mem > /sys/power/state
Le mode 'mem', aussi appelé 'Suspend to RAM' est le mode d'endormissement le plus profond disponible ne nécessitant pas un redémarrage du système au réveil. Ici, les processus espace utilisateur et noyau sont gelés, les CPU non-boot sont coupés, les périphériques sont mis en état lowpower. La RAM est mise dans un mode de basse consommation (self-refresh) durant lequel les données en RAM sont gardées. Les gains en terme de consommation apportés par ce mode dépendent du matériel et des sources de réveil activées, mais ces gains peuvent être conséquents. Ce mode est d'autant plus intéressant que le temps de réveil reste relativement court, de l'ordre de la seconde. Le support de ce mode est cependant très dépendant de la plateforme matérielle et le débogage d'un driver supportant mal ce mode peut être compliqué.
disk
echo disk > /sys/power/state
Le mode 'disk', parfois appelé "hibernation" est un peu différent, dans le sens où la RAM sera complètement éteinte. Il s'agit de faire l'équivalent d'un suspend-to-ram, puis de copier le contenu de la RAM sur un espace mémoire persistant, tel qu'un disque dur. On peut ainsi couper l'alimentation de beaucoup plus de composants, voire de l'intégralité du système.
La sortie de ce mode est cependant plus longue, car elle implique de repasser par la procédure de boot classique puis de recharger la RAM précédemment enregistrée, mais reste plus rapide qu'un boot from-scratch puisque l'initialisation des processus en espace utilisateur est déjà effectuée.
Réveil du système
Lorsque le système est endormi, il faut bien entendu pouvoir le réveiller. Les différentes sources de réveil disponibles vont dépendre de l'état d'endormissement dans lequel le système est entré. Si le système est en suspend-to-disk, les sources de réveil sont en général très restreintes car la plupart des périphériques seront éteints. Dans tous les cas, les sources de réveil disponibles sont déterminées par le matériel ainsi que certains firmwares bas niveau (le BIOS par exemple).
Le choix des sources de réveil se fait encore une fois au travers du sysfs, grâce à l'interface 'power' des drivers et devices.
Le fichier 'wakeup' peut prendre deux valeurs : 'enabled' ou 'disabled', permettant d'activer ou de désactiver un réveil du système par ce périphérique. Si ce fichier n'est pas présent, c'est tout simplement que le périphérique n'a pas la capacité matérielle de réveiller le système (ou bien que ce n'est pas implémenté).
Le fichier 'wakeup_count' va reporter le nombre de fois que l'interruption liée à ce périphérique a réveillé le système. Attention, il est possible que les évènements de réveil ne soient comptés qu'au niveau du driver du bus et non pas de votre périphérique. Dans l'exemple suivant, un contrôleur USB sur le bus PCI réveille le système. L'évènement de réveil est alors rapporté au niveau du pilote PCI et non du périphérique USB.
# Exemple : Réveil par évènement USB sur la souris de mon laptop (Dell Latitude E5550) # Le controleur USB est situé sur le bus PCI, c'est donc le driver PCI qui reportera l'interruption # de wakeup. Je sais par avance que ma souris USB est branchée sur ce port de mon controleur USB. # (Test simple : Si je débranche ma souris, /sys/devices/pci0000:00/0000:00:14.0/usb1/1-2/ disparaît du sysfs) # Consultation du nombre de réveil du système causés par ce périphérique :/sys/devices/pci0000:00/0000:00:14.0# cat power/wakeup_count 0 # Nous allons configurer directement le controleur USB, qui va alors configurer tous ses parents. :/sys/devices/pci0000:00/0000:00:14.0# cd usb1/1-2/power # Par défaut, le réveil est désactivé pour ce périphérique :/sys/devices/pci0000:00/0000:00:14.0/usb1/1-2/power# cat wakeup disabled # On active le réveil :/sys/devices/pci0000:00/0000:00:14.0/usb1/1-2/power# echo enabled > wakeup # On s'endort en mode freeze :/sys/devices/pci0000:00/0000:00:14.0/usb1/1-2/power# echo freeze > /sys/power/state # On appuie sur le bouton de la souris, qui cause alors le réveil du système. Lorsque 'wakeup' est # à 'disabled', rien ne se passe, il faut alors appuyer sur le bouton 'power' pour causer un réveil. # Allons consulter le compteur de réveil du driver PCI :/sys/devices/pci0000:00/0000:00:14.0/usb1/1-2/power# cd ../../.. # On constate que le réveil a bien été généré par ce périphérique :/sys/devices/pci0000:00/0000:00:14.0# cat power/wakeup_count 1
Il est possible de consulter l'ensemble des sources de réveil activées sur le système et de voir lesquelles ont causé des réveils dans le debugfs, si celui-ci est activé et monté, en consultant le fichier '/sys/kernel/debug/wakeup_sources'
Conclusion
Nous avons pu voir un aperçu des techniques de power-management dans le noyau. Il faut tout de même tenir compte que l'implémentation de ces différents frameworks dépendra du matériel et des drivers disponibles. Ainsi les fonctionnalités et l'API de la gestion de l'énergie dépendent fortement de la version de Linux utilisée.
Les préoccupations énergétiques sont tout de même de plus en plus prises au sérieux par les développeurs. Auparavant considérés comme sources de bugs et instabilités, les composants de gestion de l'énergie ont vu de grosses refactorisations, évolutions et formalisations au cours des dernières années. On s'approche aujourd'hui d'un energy-aware scheduler fonctionnel et la gestion du DVFS se généralise à tous les composants du système.
Les matériels évoluent, nous ne sommes plus aujourd'hui à l'ère de la course au gigahertz, désormais chaque milliwatt économisé devient un argument commercial supplémentaire pour les fabriquants. Le noyau Linux et sa communauté de développeurs suit le rythme et va continuer de proposer de plus en plus de techniques avancées pour permettre aux utilisateurs et développeurs de contrôler au mieux la consommation de leurs systèmes.
Ressources utiles
- Mode "Suspend to disk" : https://lwn.net/Articles/505683/
- cpuidle : https://lwn.net/Articles/384146/
- Power-Management QoS et PM Domaines par le mainteneur du PM Core : https://events.linuxfoundation.org/images/stories/pdf/lceu2012_wysocki.pdf
- Documentation noyau du framework Qos : https://www.kernel.org/doc/Documentation/power/pm_qos_interface.txt
- Vue d'ensemble du Power Management : http://events.linuxfoundation.org/sites/events/files/slides/Intro_Kernel_PM.pdf
- Documentation des modes d'endormissement : https://www.kernel.org/doc/Documentation/power/states.txt