Ce document présente comment les entreprises industrielles peuvent exploiter les données générées par leurs machines et capteurs pour créer de la valeur, en mettant en place des architectures robustes et optimisées. Nous aborderons le parcours complet de l’information, depuis l’acquisition en usine jusqu’à son traitement dans un centre de données, en détaillant les technologies, outils et méthodes adaptées aux environnements embarqués.
Avant de rentrer dans le vif du sujet, la 4ème révolution industrielle en une image:

1. Contexte et enjeux : l’industrie connectée à la source
À l’heure de l’Industrie 4.0, chaque machine et capteur devient une source de données numériques en continu. Pourtant, en moyenne, 70 % des données collectées restent inexploitées (forrester.com -> "Hadoop is Data's Darling For A Reason"), un constat encore plus flagrant dans les entreprises industrielles peu avancées dans leur transformation digitale.
Le défi technique consiste à transformer ce "trésor numérique" en informations stratégiques et opérationnelles. Autrefois réservées à une visualisation locale par les opérateurs, ces données peuvent aujourd’hui être collectées via des protocoles dédiés – qu’il s’agisse de réseaux industriels (comme le bus CAN ou Modbus) ou de protocoles IoT (MQTT, CoAP) – et transmises en temps réel grâce à des solutions d’Edge Computing et de pipelines de données.
Par exemple, une ligne de production équipée de capteurs de température, de vibrations et de consommation électrique peut générer des signaux bruts à haute fréquence. Ces signaux, une fois numérisés et prétraités, peuvent révéler des tendances permettant de prévenir une panne ou d’optimiser les réglages machines.
2. Du capteur à l’analytique : le parcours technique de la donnée
2.1 Du signal brut au data lake
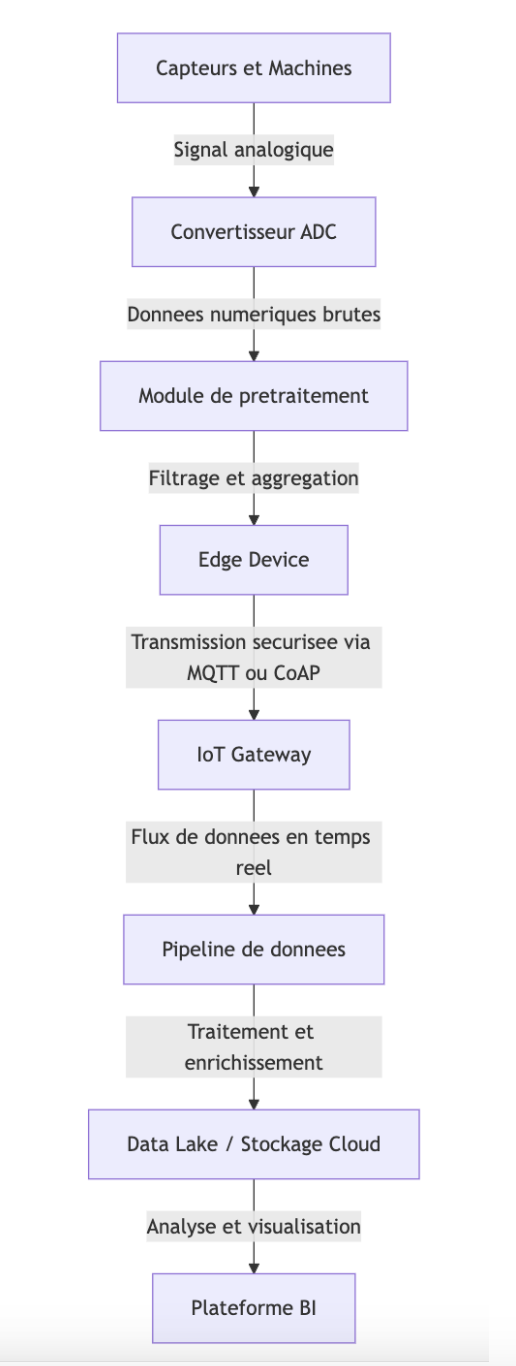
Acquisition et traitement des signaux bruts
Les signaux bruts proviennent directement des capteurs installés sur les machines. Ces signaux, souvent analogiques, sont convertis en données numériques via des ADC (convertisseurs analogique-numérique) intégrés dans les systèmes embarqués. Par exemple, dans un environnement industriel, un capteur de température peut mesurer en temps réel les variations de chaleur sur une machine. Ces données brutes sont ensuite souvent agrégées localement par un microcontrôleur ou une carte d’acquisition, qui applique des filtres pour réduire le bruit et extraire les valeurs significatives.
Vers le data lake
Une fois prétraitées, les données doivent être centralisées pour être analysées à grande échelle. C’est ici qu’intervient le concept de data lake, une architecture de stockage permettant de conserver des données structurées et non structurées à l’état brut. Des solutions comme Apache Hadoop, AWS S3 ou encore Azure Data Lake Storage sont parfois les composants de base pour cela. Le data lake permet de conserver les informations machines au coté des données métiers. L’entreprise met ensuite en place des analyses exploratoires (EDA – Exploratory Data Analysis) ou des traitements par intelligence artificielle sur l’ensemble de ses données pour en tirer de la valeur.
Ces analyses peuvent prendre plusieurs formes selon les objectifs métier:
- En premier lieu, l’analyse exploratoire des données (EDA) vise à mieux comprendre la structure, la distribution et la qualité des données collectées. Cette phase permet de détecter des valeurs aberrantes, des corrélations entre informations ou des tendances globales. Cette étape est réalisée à l’aide d’outils comme Python (et ses librairie comme Pandas, Seaborn, Plotly), Jupyter Notebooks ou des notebooks intégrés dans des environnements cloud (ex : Amazon SageMaker, Databricks).
- À un niveau plus avancé, ces données prétraitées peuvent alimenter des modèles de machine learning pour des usages métiers concrets :
- Détection d’anomalies en temps réel : en entraînant un modèle à reconnaître le comportement "normal" d’un capteur, on peut ensuite repérer des écarts significatifs qui signalent une dérive machine ou un problème de qualité.
- Maintenance prédictive : à partir de l’historique des informations des télémétries, on peut entraîner des modèles de classification (Random Forest, réseaux de neurones...) pour prédire la probabilité de défaillance d’un équipement et anticiper les interventions.
- Optimisation de la consommation énergétique : pour repérer des marges d’amélioration sur le rendement énergétique de l’atelier.
- Segmentation des cycles de production : Avec le clustering (K-means, etc.), il est possible de regrouper les séquences de fabrication selon des profils similaires et d’identifier des causes communes aux écarts de qualité par exemple.
Dans la pratique, ces modèles sont développés dans des environnements de data science comme Jupyter/PyCharm, ou via des plateformes industrielles intégrant des capacités IA comme Seeq ou Ignition avec des modules ML intégrés.
- Enfin, les résultats des analyses sont restitués sous forme de tableaux de bord , intégrés aux systèmes existants (MES, SCADA, ou ERP) ou accessibles via des outils de visualisation comme Power BI, Grafana, ou Tableau.
2.2 Vers l’usine digitalisée : intégration et pilotage
De la collecte à la centralisation
L’intégration des données requiert des outils capables de gérer la diversité et le volume d’informations issues des capteurs. Les plateformes IoT jouent ici un rôle central. Ces plateformes (telles que ThingsBoard, ou même des solutions industrielles comme PTC ThingWorx) offrent des interfaces pour la configuration des appareils, la gestion des flux de données et la mise en place d’alertes.

Ces plateformes IoT s’appuient généralement sur des protocoles de communication légers et temps réel, dont MQTT (Message Queuing Telemetry Transport) est l’un des plus répandus dans l’industrie. MQTT a l’avantage d’être conçu pour fonctionner sur des réseaux à faible bande passante, avec une empreinte mémoire minimale et une communication asynchrone très bien adaptée aux environnements distribués (edge, cloud, mobile).
Pour encore alléger les échanges, MQTT (et d'autres systèmes) utilise des formats de messages binaires comme Protobuf (Protocol Buffers) ou MessagePack, qui permettent de réduire la taille des messages transmis. Cela est particulièrement utile dans les environnements où chaque octet compte (comme sur les réseaux LoRaWAN, 3G intermittents).
En termes d’architecture, ces messages sont transmis par l'intermédiaire d'un broker MQTT, qui agit comme un gestionnaire central de la communication entre les capteurs/automates (publishers) et les services de traitement (subscribers). Dans un contexte pour faire des prototypes, des brokers légers comme Eclipse Mosquitto peuvent suffire. Ils sont simples à déployer mais ils ne répondent pas aux exigences de montée en charge attendues en production.
Pour les systèmes industriels à grande échelle, on s’orientera vers des brokers plus scalables, tels que :
- HiveMQ : une solution industrielle éprouvée, offrant la gestion de clusters, une intégration poussée avec les architectures cloud, le support du TLS, du WebSocket.
- RabbitMQ (avec extension MQTT) : une alternative open-source qui peut combiner MQTT avec d’autres protocoles (AMQP, STOMP…) dans des environnements hybrides.
Ces brokers enrichissent les messages de métadonnées utiles (horodatage, ID équipement, contexte opérationnel…), et les redirigent vers les systèmes de traitement en aval (data lake, plateformes d’analyse).
Pilotage en temps réel et rétroaction
Une fois centralisées, les données peuvent être exploitées pour piloter l’ensemble du processus de production. Par exemple, une usine peut utiliser des dashboards en temps réel basés sur Grafana (solution open source de monitoring) ou Kibana (solution de visualisation faisant partie de la suite Elastic) pour visualiser l’état de ses lignes de production. Ces outils, couplés à des bases de données temporelles comme InfluxDB ou Timestream d’AWS, permettent de suivre des indicateurs clés tels que le throughput (débit ou cadence de production par exemple), l’efficacité énergétique ou la disponibilité des équipements.
En parallèle, l’intégration avec des systèmes ERP et MES (Manufacturing Execution Systems) permet d’optimiser la planification de la production. Un des graals recherchés par les gestionnaires dans une usine serait par exemple, lorsqu'une anomalie est détectée sur une machine, que le système réajuste automatiquement les ordres de fabrication ou planifie une intervention de maintenance préventive.
3. Solutions technologiques adaptées aux environnements embarqués
Plateformes IoT
Les plateformes IoT offrent une gestion complète du cycle de vie des objets connectés. Elles permettent :
- Le déploiement et la configuration : Les appareils peuvent être provisionnés à distance avec des certificats de sécurité, des configurations réseau et des règles de collecte de données.
- La communication sécurisée : Grâce à des protocoles sécurisés (TLS), les données sont protégées lors de leur transit, ce qui est essentiel dans des environnements industriels. Car les données remontées donne des informations directes sur l’activité.
- La visualisation et l’alerte : Des interfaces web conviviales permettent de créer des tableaux de bord, de configurer des seuils d’alerte et de déclencher des actions automatiques (comme l’envoi d’un SMS ou l’activation d’un système de secours).
Par exemple, une plateforme telle que ThingsBoard peut gérer des milliers de capteurs en simultané, offrant des API REST et des connecteurs pour intégrer les données dans des systèmes tiers.
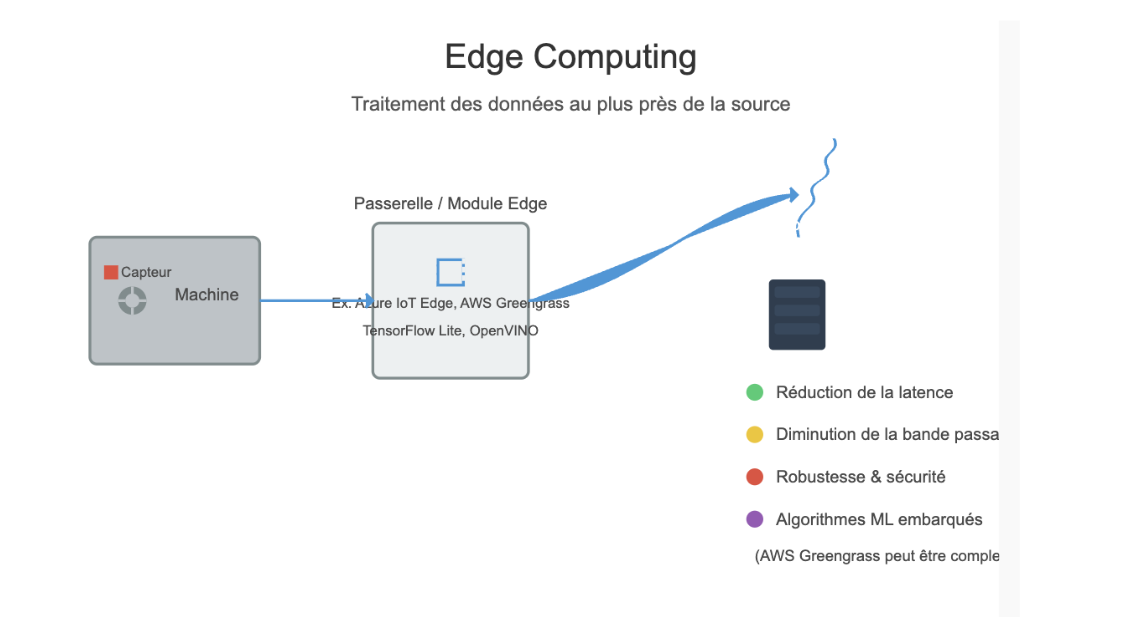
Edge Computing
L’Edge Computing consiste à traiter les données au plus près de leur source. Cette approche présente plusieurs avantages :
- Réduction de la latence : En traitant les données localement, les décisions critiques (comme l’arrêt d’une machine en cas de défaut) peuvent être prises en quelques millisecondes.
- Diminution de la bande passante : Le prétraitement des données permet d’envoyer uniquement les informations essentielles vers le centre de données, réduisant ainsi la charge sur les réseaux industriels.
- Robustesse et sécurité : Des systèmes d’Edge Computing, tels que Azure IoT Edge ou AWS Greengrass (module Java permettant de faire certains traitements AWS en local au plus près de vos machines physiques), peuvent être déployés sur des passerelles industrielles robustes (souvent basées sur des architectures ARM ou x86) et intégrer des modules de sécurité pour isoler les traitements critiques. Par contre, il faut savoir que certains modules Edge sont très complexes à appréhender; c’est le cas de AWS Greengrass.
Concrètement, un module Edge peut exécuter des opérations spécifiques sur les données ainsi qu’appliquer des algorithmes de machine learning embarqués, par exemple en utilisant TensorFlow Lite ou OpenVINO, afin de détecter en temps réel des comportements anormaux dans les vibrations ou les températures d’une machine par exemple.
Pipelines de données
Les pipelines de données constituent le squelette de la transformation des données collectées. Elles automatisent l’ensemble du parcours depuis la collecte jusqu’à l’analyse finale.
Des outils open source comme Apache Kafka sont utilisés pour créer des pipelines robustes et scalables. Ces pipelines se chargent de :
- La collecte en continu : Kafka, par exemple, permet de gérer des flux de données en temps réel avec une haute disponibilité et une tolérance aux pannes.
- Le traitement en streaming : Apache Flink ou Spark Streaming permettent d’effectuer des traitements en temps réel (agrégation, filtrage, enrichissement) sur les flux de données.
- La mise en forme et le stockage : Après traitement, les données sont stockées dans des bases de données NoSQL (comme Cassandra, MongoDB) ou directement dans des data lakes dans le cloud.
4. Bénéfices métier et perspectives
La centralisation et l’analyse fine des données apportent de nombreux avantages pour les entreprises industrielles :
- Optimisation des processus de production :
L’analyse en temps réel des données permet d’identifier les goulets d’étranglement et d’ajuster les paramètres de production. Des études montrent que les usines data-driven peuvent améliorer leur cadence de production (throughput) de 10 à 30 % (source mckinsey.com -> "Capturing the true value of Industry 4.0"). Par exemple, en analysant les cycles de fonctionnement et les temps d’arrêt, une usine peut recalibrer les machines pour maximiser l’efficacité. - Maintenance prédictive :
La surveillance continue de paramètres critiques (vibrations, température, courant électrique) permet d’anticiper les pannes. L’implémentation d’algorithmes de machine learning embarqués sur des systèmes Edge permet de détecter des anomalies avant qu’elles ne conduisent à des arrêts de production coûteux. Mais, en réalité, peu d'entreprises industrielles ont lancé ce genre de chantier technique. Et pourtant, cela permet une réduction significative des coûts de maintenance et une augmentation de la disponibilité des équipements. Des entreprises comme Smile peuvent vous accompagner pour ce genre de missions qui consistent à embarquer des modèles de machine learning dans le système de Edge Computing - Amélioration de la qualité et traçabilité :
Grâce à une collecte centralisée, les dérives de qualité (par exemple, une variation anormale de température indiquant un défaut dans le processus de fabrication) peuvent être immédiatement identifiées et corrigées. Les informations historiques stockées dans le data lake permettent également de retracer l’origine d’un défaut et de mettre en place des actions correctives ciblées. - Planification agile et optimisation logistique :
La centralisation des données (stocks, volumes produits, commandes) permet une vision globale de l’activité industrielle. Des outils analytiques, combinés à des dashboards interactifs, offrent aux responsables une vue à 360° des opérations, facilitant ainsi la synchronisation entre la production, la supply chain et la stratégie globale de l’entreprise.
5. En route vers l’usine connectée
Pour concrétiser ces perspectives, l’implémentation d’une solution complète repose sur l’intégration de plusieurs systèmes et outils :
- Infrastructure embarquée : Capteurs, microcontrôleurs et cartes d’acquisition connectés via des protocoles industriels ou IoT.
- Passerelles et Edge Computing : Dispositifs robustes capables de traiter les données en local, équipés de modules de sécurité et de connectivité (Ethernet, WiFi, 4G/LTE).
- Plateformes de gestion IoT : Logiciels comme ThingsBoard, Kuzzle ou Kaa qui permettent de gérer le déploiement, la configuration et la supervision des équipements.
- Pipelines de données : Utilisation d’Apache Kafka pour la collecte en temps réel, Apache NiFi pour l’orchestration des flux et Apache Spark Streaming pour l’analyse en continu.
- Data Lake et solutions d’analyse : Stockage des données brutes et transformées dans des systèmes comme Hadoop, couplé à des outils de BI (Business Intelligence) tels que Grafana ou Kibana pour l’analyse visuelle et la génération de rapports.
Le "bruit" des machines devient une information exploitable par l’ensemble des services métiers.
Conclusion
L’enjeu technique n’est pas uniquement de collecter des données, mais de concevoir une architecture capable de garantir la fiabilité, la sécurité et l’efficacité du transfert et du traitement des informations. En combinant des capteurs performants, des plateformes/solutions IoT adaptées, un traitement Edge intelligent et des pipelines de données robustes, les entreprises industrielles peuvent passer d’une exploitation locale et réactive des informations à une approche globale, proactive et prédictive.
Cette transformation digitale, en intégrant des concepts comme le data lake, l’Edge Computing, permet d’optimiser la production, de réduire les coûts de maintenance et même d’améliorer la qualité de la production. C’est ainsi que le "bruit" des machines se mue en une ressource stratégique pour l’entreprise.