Le son
Le son est une onde mécanique qui peut être générée par un signal analogique, ce qui rend son traitement en informatique délicat mais possible.

L'oreille humaine a toute son importance dans la manière d'utiliser l'outil informatique, car celui-ci ne permet pas un rendu parfait. Notre oreille permet d'entendre des sons dans une bande de fréquence approximative de 16Hz à 22kHz (souvent réduite de 20Hz à 20kHz, pour des raisons de commodité, mais déjà excessivement large pour le commun des mortels ) qui dépend de la personne et du milieu sonore. Dans cette bande de fréquence, l'humain a des capacités de discernement plus précises dans la bande de 2kHz à 5kHz. La voix humaine est basée sur une fondamentale entre 85Hz et 255Hz, les harmoniques pourront varier entre 300Hz et 3400Hz pour la parole. En chant, la fondamentale variera de 70Hz (basse) à 1200Hz (soprano).
Le second facteur de la qualité du son est la différenciation des sons dans l'environnement, ce qui est de l'ordre du son et celui du bruit. Cela dépend dans un premier temps de l'intensité du son qui n'est autre que la pression dans l'air provoquée par l'onde. Notre oreille permet de détecter une pression de 20 mP et subira des lésions dès 20P dans notre environnement. Comme la pression atmosphérique dépend aussi de notre environnement, l'intensité se mesure en variation de pression sur une échelle logarithmique de 16,5dB à 130dB par rapport à une référence de 20 μPa.
LP = 20 * Log10 ( Peff Prel ) L20P = 20 * Log10 ( 20P 20μP ) = 120dB

Notre oreille est capable de détecter un son s'il n'est pas recouvert par un autre d'une intensité supérieure à 25% du premier. Cette différentiation varie avec le niveau sonore et la fréquence, elle est mesurée en dB et tourne entre de 1,5 et 0,3 dB.
La transformation numérique
L´échantillonnage
La numérisation de signaux sinusoïdaux utilise la méthode d’échantillonnage qui permet de traduire celui-ci en niveaux discrets sur un intervalle de temps inférieur à sa période.
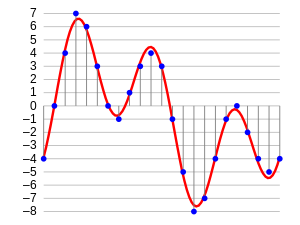
Le taux d'échantillonnage doit être supérieur à 2 fois la fréquence la plus élevée, ce qui est décrit par le théorème de Nyquist-Shannon. La fréquence d'échantillonnage est donc fonction du type de son à transformer :
- 8kHz pour la voix en téléphonie ;
- 16kHz pour les codecs de VoIP ;
- 44,1kHz pour un CD audio de musique ;
- 48kHz pour la télévision numérique et les DVD ;
- 96kHz - 192kHz pour le DVD audio et Blu-ray ;
- 353,8kHz - 22,5792 GHz pour super audio CD - Mais codage DSD sur un bit, donc pas comparable au PCM.
Pour de la musique, 48kHz est en théorie suffisant pour une restitution parfaite. L'usage d'une fréquence supérieure ne permettrait que d'échantillonner des ultra-sons. Ceux-ci peuvent générer des artefacts audios dans des situations particulières qui sont nuisibles à la qualité du son.
Note: Percevoir une différence à une fréquence supérieur à 44,1 kHz (soit 2,2 * la fréquence perçue la plus haute) semble incohérent. Mon avis personnel est que cela pourrait venir du DAC, qui utilise un système de ré-échantillonage ou une horloge de mauvaise qualité en 44.1kHz, où alors que le master de la version 96kHz est meilleur que celui utilisé pour la version 44.1kHz (ce qui semblerait être souvent le cas dans les productions Hi-Res de DVD audio).
Le résolution sonore
Le rapport Signal/Bruit, ouSNR (S/N), se définit grâce à la précision de la quantification du niveau. Avec un codage sur un entier il est possible de représenter un certain nombre de variations de niveau. C'est la quantification de la valeur analogique, chaque valeur étant une modulation d'impulsion codée ou en anglais PCM. La quantification apporte une erreur sur la valeur analogique réelle (ou distorsion) qui se mesure en dB.
- 8bits pour un SNR de 48dB, utilisé en téléphonie ;
- 16bits pour un SNR de 96dB, utilisé sur les CD audio ;
- 21bits pour un SNR de 123dB, la perception de l'oreille ;
- 24bits pour un SNR de 144dB, utilisé pour les enregistrements professionnels.
Il est aussi possible d'utiliser une notation en virgule flottante pour le niveau sonore, ce qui permet d'avoir un SNR variable en fonction de la bande de fréquence.
La qualité du son dépend donc de la précision de la quantification du niveau sonore et de la fréquence d'échantillonnage. Un enregistrement à 14bits en 768kHz sera de qualité identique à 16bits 48kHz.
Bien sûr chaque transformation analogique/numérique fait perdre de la qualité , mais il ne faut pas la confondre avec celle venant des encodages successifs qui ne sont pas abordés dans le présent article.
La latence, les coupures, le bruit
D'autres éléments de la perception du son sont importants lors de la restitution d'un son. L'un d'eux est ce qu'il serait possible de nommer la persistance auditive. En effet l'oreille humaine est incapable de détecter un trou très court dans un son ou un décalage de deux sons identiques venant de sources différentes, ou encore un décalage entre le son et une image. Il en va de même dans le sens inverse, l'oreille ne peut pas distinguer un son trop court. Ce temps de persistance varie selon les personnes, mais en dessous de 10ms, il est impossible de faire la distinction de la modification. Au delà de 100ms, la variation est trop significative pour être compensée.
Pour limiter les effets indésirables lors de défauts dans la transmission de flux sonore, il est possible d'ajouter du bruit. Celui-ci va permettre de couvrir soit un trou, soit une distorsion ou un autre bruit. Ce bruit doit être choisi en fonction du cas à traiter. En effet un bruit aléatoire va couvrir un autre bruit plus cyclique, un bruit sur certaines fréquences va permettre d'effacer les trous.
Il y a trois types de bruits très connus et utilisés. Les trois sont formés par une association de toutes les fréquences audibles, c'est l'intensité relative de chaque fréquence qui va varier:
- Le bruit blanc : toutes les fréquences ont la même intensité ;
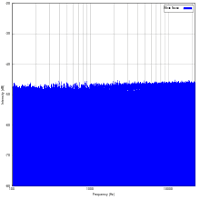
Il a l'avantage d'être plus facile à générer et il est souvent confondu avec un bruit aléatoire.
- Le bruit gris : les fréquences médiums sont atténuées par rapport aux extrêmes ;
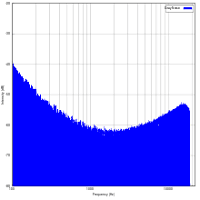
Son grand avantage vient qu'il est moins perceptible qu'un vide dans le son. - Le bruit rose: plus les fréquences sont basses, plus le niveau est important ;
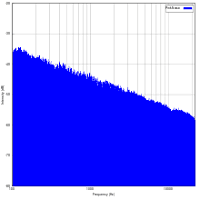
Il est utilisé pour couvrir un autre bruit.
Une des plus grandes complexités dans la transmission de flux sonore est la gestion de la latence, et des trous. Cela est particulièrement vrai dans la communication où les contraintes sont nombreuses et contradictoires :
- le débit peut être variable, en particulier dans des conditions de déplacement ;
- la latence entre l’émission et la réception ne doit pas dépasser 100ms, pour ne pas perturber la compréhension lors d'un dialogue ;
- des échantillons peuvent être perdus en plus ou moins grand nombre, en fonction de la qualité du son transmis ;
- un encodage du son performant en terme de qualité demande un grand nombre d'échantillons.
Les algorithmes utilisés devront permettre de trouver le meilleur compromis en fonction des conditions. Il est plus facile d'avoir une bonne qualité sur une communication voix avec un relais radio dédié, alors que la sonorisation d'une salle de spectacle en Wifi sera quasi impossible (pour l'instant). Parmi ces algorithmes on retrouve :
- le remplissage des trous par du bruit ;
- les buffers avec démarrage à seuil (scatter/gather et thresholds), avec seuil fixe ou variable, avec simple ou double seuil ;
- la gestion du retard des échantillons, avec des protocoles comme RTP ou DVB.
- le filtrage des bandes passantes utiles ;
- la compression du son.
A lire:
https://people.xiph.org/~xiphmont/demo/neil-young.html
http://lavryengineering.com/pdfs/lavry-sampling-theory.pdf
https://www.audiocheck.net/blindtests_index.php
Alsa API
Les applications doivent utiliser la librairie asound et une autre bibliothèque au dessus de celle-ci comme PulseAudio ou Jack.
Alsa va permettre de répondre à un certain nombre des problèmes évoqués. Elle permet de gérer la quantité d'échantillons nécessaires à une bonne communication, au filtrage et au mixage avec un bruit.
La librairie asound, outre une API de fonctions très large, offre de nombreuses fonctionnalités. Celle-ci profite de l'usage de plugin, pour créer des cartes son virtuelles et ajouter des accessoires, comme le mixage, des filtres ou du ré-échantillonnage. Cette partie ne sera pas abordée dans le présent article.
Nous nous contenterons d'une approche basique de l'API, dont la documentation est disponible sur https://www.alsa-project.org/alsa-doc/alsa-lib/ , avec tout de même la première approche de la gestion de la latence.
Son utilisation peut être divisée en cinq parties :
- l'ouverture et la configuration du matériel ;
- la configuration de la librairie asound (optionnelle) ;
- le transfert des échantillons ;
- la fermeture du matériel ;
- le contrôle de la sortie analogique.
La configuration de la partie logicielle de la librairie n'est pas abordée non plus. Elle correspond à ce qui peut être fait lors de la configuration de la librairie.
Introduction
Le fichier d'en-tête est alsa/asoundlib.h et la bibliothèque est libasound.so.
player.c:
#include <alsa/asoundlib.h>
Makefile:
$(TARGET):
$(CC) -o $@ $< -lasound
Ouverture et configuration
Dans un premier temps il faut choisir la carte son à utiliser. Celles-ci sont nommées par un index de carte et un second index d'interface. Le plus souvent l'index d'interface est 0 et c'est la valeur par défaut. Le nom de l'interface à utiliser ressemble le plus souvent à hw:0.0. Il est courant que plusieurs cartes son soient disponibles sur le système. Il est donc possible de définir une carte son par défaut dont le nom est default.
player.c :
snd_pcm_t *playback_handle;
char *soundcard = strdup("hw:0,0");
snd_pcm_open(&playback_handle, soundcard, SND_PCM_STREAM_PLAYBACK, 0);
L'opération suivante consiste à retrouver la configuration actuelle de la carte.
player.c :
snd_pcm_hw_params_t *hw_params; snd_pcm_hw_params_malloc(&hw_params); snd_pcm_hw_params_any(playback_handle, hw_params);
Une fois que les paramètres matériels sont connus, il faut les mettre en concordance avec les besoins de l'application. Les paramètres les plus importants sont :
- le sens du flux audio : une restitution ou un enregistrement audio ;
- le nombre de voies et leurs imbrications dans le flux ;
- la résolution des échantillons : entier ou flottant, 8, 16, 24 ou 32 bits, l'ordre des octets LE ou BE ;
- la fréquence d’échantillonnage.
Pour un jeu d'un flux de type CD audio nous aurons un paramétrage du type Entier 16bits Little Endian Stéréo entrelacé à 44100 Hz.
player.c :
int channels = 2; snd_pcm_hw_params_set_channels(playback_handle, hw_params, channels); snd_pcm_hw_params_set_access(playback_handle, hw_params, SND_PCM_ACCESS_RW_INTERLEAVED); snd_pcm_format_t pcm_format = SND_PCM_FORMAT_S16_LE; snd_pcm_hw_params_set_format(playback_handle, hw_params, pcm_format);
Il est nécessaire de vérifier que chaque valeur peut être acceptée par la carte. Pour ce qui est de la fréquence le choix est plus ouvert, en effet celle-ci dépend des horloges qui lui sont disponibles et toutes les valeurs ne sont pas forcément utilisables. Il est donc nécessaire de demander à la carte la valeur qu'elle peut admettre comme étant la plus proche de celle souhaitée.
player.c :
unsigned int rate = 44100; snd_pcm_hw_params_set_rate_near(playback_handle, hw_params, &rate, NULL);
Un flux audio ne doit pas être interrompu, or le noyau est incapable de tenir une fréquence d'échantillonnage de 44kHz. Il est donc nécessaire d'envoyer un grand nombre d'échantillons à la carte qui les ordonnancera au rythme souhaité. La carte doit aussi préparer ces paquets de données, et il est préférable de lui soumettre plusieurs paquets. Ceux-ci sont appelés les périodes.
Mais tout cela modifie aussi la latence dans le son. En effet plus le nombre d'échantillons est grand, plus long sera le temps entre l'insertion d'un échantillon sur la carte et son audition (et inversement pour les enregistrements). Il est donc nécessaire de bien choisir le nombre de périodes et leur taille en fonction du besoin.
- pour une communication la latence doit être la plus courte possible de l'ordre de 10ms ;
- pour l'utilisation de codec performant en terme de place, il est nécessaire d'avoir des périodes bien plus longues.
La latence se calcule comme suit :
Latency = nbsamples / rate
player.c:
int periods = 3; snd_pcm_hw_params_set_periods(playback_handle, hwparams, periods, 0); int nbsamples = 1024; snd_pcm_hw_params_set_period_size(playback_handle, hwparams, nbsamples, 0);
Dans notre cas la latence est de :
Latency = 1024 / 44100 = 23,22ms
La librairie asound permet de configurer 3 informations sur la pile des échantillons:
- le nombre de périodes (periods), qui doit être supérieur ou égal à 3 ;
- la taille d'une période (period_size), qui se mesure en nombre d'échantillons ;
- la taille complète de la pile (buffer_size), qui est le produit de la taille d'une période et du nombre de périodes.
Notre jeu de paramètres est prêt, il ne reste plus qu'à le faire prendre en compte par la carte comme nous avons récupéré le jeu précédent.
player.c :
snd_pcm_hw_params(playback_handle, hwparams); snd_pcm_prepare(playback_handle); snd_pcm_hw_params_free(hw_params);
Notre fonction d'initialisation devient :
player.c :
snd_pcm_t *playback_handle;
char *soundcard = strdup("default");
snd_pcm_open(&playback_handle, soundcard, SND_PCM_STREAM_PLAYBACK, 0);
snd_pcm_hw_params_t *hw_params;
snd_pcm_hw_params_malloc(&hw_params);
snd_pcm_hw_params_any(playback_handle, hw_params);
int channels = 2;
snd_pcm_hw_params_set_channels(playback_handle, hw_params, channels);
snd_pcm_hw_params_set_access(playback_handle, hw_params, SND_PCM_ACCESS_RW_INTERLEAVED);
snd_pcm_format_t pcm_format = SND_PCM_FORMAT_S16_LE;
snd_pcm_hw_params_set_format(playback_handle, hw_params, pcm_format);
unsigned int rate = 44100;
snd_pcm_hw_params_set_rate_near(playback_handle, hw_params, &rate, NULL);
int periods = 2;
snd_pcm_hw_params_set_periods(playback_handle, hwparams, periods, 0);
int nbsamples = 1024;
snd_pcm_hw_params_set_period_size(playback_handle, hwparams, nbsamples, 0);
snd_pcm_hw_params_set_buffer_size(playback_handle, hwparams, nbsamples * periods);
snd_pcm_hw_params(playback_handle, hwparams);
snd_pcm_prepare(playback_handle);
snd_pcm_hw_params_free(hw_params);
free(soundcard);
Transfert des échantillons pour une restitution sonore
Le transfert est une simple écriture de paquets d'échantillons sur l'interface de ALSA. Il est essentiel que chaque échantillon soit au format qui a été paramétré précédemment et il est préférable que chaque paquet contienne le nombre prévu d'échantillons pour une période.
Nous prenons le cas d'une fonction générant du bruit aléatoire pour chacune des voies.
player.c :
int generator_init(void)
{
unsigned int seed,
int fd = open("/dev/random", R_OK);
sched_yield();
read(fd, &seed, sizeof(seed);
close(fd);
srandom(seed);
}
void generator(int16_t *samples, int nbsamples, int16_t max)
{
int i,
for (i = 0; i < nbsamples; i++)
{
int16_t *left = &samples[i * 2];
int16_t *right = &samples[i * 2 + 1];
*left = random() * max / RAND_MAX;
*right = random() * max / RAND_MAX;
}
}
La boucle principale est donc tout simplement :
player.c:
int play(int nbsamples)
{
int run = 1;
int16_t *buffer = malloc(nbsamples * sizeof(int16_t) * 2);
generator_init();
while (run)
{
generator(buffer, nbsamples, INT16_MAX);
snd_pcm_writei(playback_handle, buffer, nbsamples);
}
free(buffer);
}
Dans le cas présent, le génerateur prend peu de temps CPU et donc ne sera pas bloquant et c'est la fonction de la librairie qui imposera le rythme des données.
La carte doit fonctionner en flux tendu. Si le génerateur devenait bloquant, la librairie pourrait être sous-alimentée et la fonction snd_pcm_writei sortirait une erreur -EPIPE. Il faut alors réinitialiser la machine d'état de la librairie et la fonction de restitution devient :
Il est aussi possible de gérer indépendamment les canaux. La fonction de restitution deviendrait :
player.c:
int play(int nbsamples)
{
int run = 1;
int16_t *buffer[2];
buffer[0] = malloc(nbsamples * sizeof(int16_t));
buffer[1] = malloc(nbsamples * sizeof(int16_t));
generator_init();
while (run)
{
int ret;
generator(buffer[0], nbsamples, INT16_MAX);
generator(buffer[1], nbsamples, INT16_MAX);
ret = snd_pcm_writen(playback_handle, buffer, nbsamples);
if (ret == -EPIPE)
snd_pcm_recover(playback_handle, ret, 0);
}
free(buffer);
}
Fermeture
Comme la carte peut contenir encore des échantillons selon le besoin de l'application il peut être nécessaire d'attendre la fin de leur restitution avant la fermeture. Cela consiste à drainer les buffers résiduels :
player.c:
int finish()
{
snd_pcm_drain(playback_handle);
snd_pcm_close(playback_handle);
}
Code complet https://gist.github.com/mchalain/3eb0a88251262488d2c00fa52c371916
Contrôle de la sortie analogique
Chaque carte permet de contrôler plus ou moins la sortie analogique. Cela va du volume général du son à l'équalisation par canal.
Une carte définit et nomme des réglages qui peuvent s'apparenter à des potentiomètres et des boutons qui seraient présents à différents niveaux du circuit analogique. Ceux-ci ont donc une valeur entière ou un état on/off.
Il est nécessaire de connaitre le nom du réglage sollicité, et celui-ci peut varier selon la carte pour une même fonction. Le plus souvent le volume principal de la carte audio est appelé Master.
mixer.c :
snd_mixer_elem_t* mixerchannel;
int init(void)
{
snd_mixer_t *mixer;
snd_mixer_open(&mixer, 0);
snd_mixer_attach(mixer, "default");
snd_mixer_selem_register(mixer, NULL, NULL);
snd_mixer_selem_id_t *sid;
snd_mixer_selem_id_alloca(&sid);
snd_mixer_selem_id_set_index(sid, 0);
snd_mixer_selem_id_set_name(sid, "Master");
mixerchannel = snd_mixer_find_selem(mixer, sid);
}
mixer.c :
int setvolume(int percent)
{
long min = 0, max = 0;
snd_mixer_selem_get_playback_volume_range(mixerchannel, &min, &max);
if (percent > 100)
percent == 100;
long lvolume = percent * (max - min) / 100 + min;
snd_mixer_selem_set_playback_volume_all(mixerchannel, lvolume); }
Le volume varie entre un minimum et un maximum qui sont également spécifiques à chaque carte. Il est donc nécessaire de retrouver ces bornes avant de vouloir changer la valeur courante.
Conclusion
Cet article n'est qu'une introduction à ALSA. Deux parties importantes à l'infrastructure du son sur Linux resteraient à décrire.
La première est la configuration de la librairie ALSA et l'utilisation des plugin permettant de créer des cartes virtuelles pour améliorer les capacités de votre carte sans avoir à écrire du code.
La seconde est l'écriture de driver pour les cartes son, qui utilise une API spécifique du kernel et dont l'usage est particulier à un traitement rapide des données.