Introduction
Dans le développement de logiciels, le débogage consiste à localiser et à corriger les erreurs de code dans un programme informatique. Le débogage fait partie du processus de test logiciel et fait partie intégrante du cycle de vie du développement.
Le débogage est souvent difficile pour les programmeurs, Norman Matloff et Peter Jay Salzman disent:
Déboguer, c'est chercher une aiguille dans une botte de foin. Et dans de nombreux cas, le bug s'avère être dans la partie du programme dont vous êtes le plus sûr
Nous verrons dans cet article les outils (souvent méconnus) qui permettent de déboguer l'applicatif ou même le noyau d'un système sous Linux.
Cet article est articulé autour de deux grandes lignes; l'espace utilisateur et l'espace noyau.
Débogage en espace utilisateur
Déboguer en espace utilisateur consiste à déboguer dans l'environnement d'exécution d'une application, et donc dans un environnement non privilégié. On associe souvent l'espace utilisateur à l'espace mémoire qui lui est attribué, espace mémoire bénéficiant des différentes protections; protection mémoire, protection temporelle, etc.
Il existe plusieurs façons de déboguer dans l’espace utilisateur, nous présentons, dans cette partie, les méthodes les plus répandues.
Méthodes de traçage statique
Le débogage le plus simple (mais loin d'être le meilleur) est l'usage des fonctions de conversion de sortie formatée comme : printf, fprintf et autres dans le code. Cette méthode est connue sous le nom de USDT (user-level statically defined tracing) qui peut être traduit par “Méthode de traçage statique en espace utilisateur”.
Exemple d'application :
- printf : Nous allons utiliser la fonction "printf" pour s'assurer de la bonne réception des signaux SIGINT et SIGUSR1.
- Ecrire le code source (signal_handler.c) : voici un exemple de code simpliste ;
#include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <signal.h> /* handler SIGUSR1 and SIGINT signals */ static void sigusr1_handler(int signo) { /* In practice, never call printf within a signal handler */ if(signo == SIGUSR1) printf("I caught SIGUSR1\n"); // USDT tracing SIGUSR1 signal reception else if (signo == SIGINT) printf("I caught SIGINT\n"); // USDT tracing SIGINT signal reception } int main (void) { if (signal(SIGUSR1, sigusr1_handler) == SIG_ERR) { // Register To handle SIGUSR1 printf ("Cannot catch SIGUSR1\n"); exit (EXIT_FAILURE); } if (signal(SIGINT, sigusr1_handler) == SIG_ERR) { // Register To handle SIGINT printf ("Cannot catch SIGINT\n"); exit (EXIT_FAILURE); } while (1) pause(); return EXIT_SUCCESS;/ }Remarque : En pratique, la fonction signal est déprécié (usage pour des fins académique). Elle doit être remplacée par sigaction.
- Tester le programme : on peut utiliser la commande Linux ≪kill≫ (kill -l pour avoir la liste des signaux et le numéro de chaque) pour envoyer des signaux au programme :
kill -NUMERO_SIGNAL ./programVoici une série de test qu'on peut faire avec le programme (voir l'image ci-dessous).
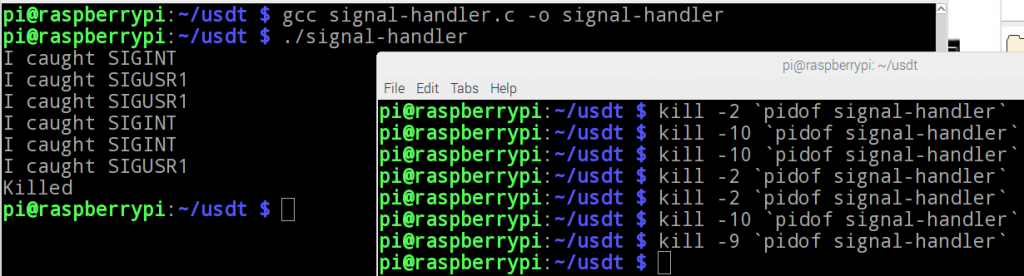
Grâce a printf, on a pu tester la réception des signaux dans notre programme.
Finalement, on a vérifié que les signaux ont été bien reçus par l'application avec printf.
Important : kill -9 (SIGKILL) est un signal qui ne peut pas être capté et géré par le processus. En effet, ce signal, lorsqu'il est reçu par le noyau, n'est pas transmis au processus par ce dernier; le noyau détruit simplement le processus.
Le système de fichiers
Les systèmes de fichiers /proc et /sys sont des pseudo système de fichiers (ils n'existent pas sur le disque), ils sont créés lors du démarrage du système.
ProcFs
Fournit des informations sur la configuration matérielle et des processus en cours d'exécution (d’où le nom proc pour “processes”).
On peut diviser le contenu de ce fichier ($ ls /proc) en deux :
Les processus
Chaque processus en cours d'exécution possède un dossier dans /proc, ces derniers sont nommés avec le PID de chaque processus (l'utilitaire "ps" parse le fichier /proc à la recherche de dossier processus).
On peut accéder au détail de chaque processus:
- /proc/pid/maps : permet de voir l’organisation de l’espace virtuel d’un processus. Nous pouvons démontrer l'usage de ce fichier avec un exemple :
- L'exemple suivant hello-smile.c : affiche un message puis appelle la fonction pause().
int main(){ printf("%s", "Hello Smile! I Love Open Source!\n"); for(;;) pause(); return EXIT_SUCCESS; }On peut maintenant lire le fichier maps qui correspond à notre programme :
$ cat /proc/`pidof hello-smile`/maps 00400000-00401000 r-xp 00000000 fc:03 6562304 /home/jugbe/hello-smile 00600000-00601000 r--p 00000000 fc:03 6562304 /home/jugbe/hello-smile 00601000-00602000 rw-p 00001000 fc:03 6562304 /home/jugbe/hello-smile 00e1a000-00e3b000 rw-p 00000000 00:00 0 [heap] 7fec97264000-7fec97424000 r-xp 00000000 fc:01 1704110 /lib/x86_64-linux-gnu/libc-2.23.so 7fec97424000-7fec97624000 ---p 001c0000 fc:01 1704110 /lib/x86_64-linux-gnu/libc-2.23.so 7fec97624000-7fec97628000 r--p 001c0000 fc:01 1704110 /lib/x86_64-linux-gnu/libc-2.23.so 7fec97628000-7fec9762a000 rw-p 001c4000 fc:01 1704110 /lib/x86_64-linux-gnu/libc-2.23.so 7fec9762a000-7fec9762e000 rw-p 00000000 00:00 0 7fec9762e000-7fec97654000 r-xp 00000000 fc:01 1704106 /lib/x86_64-linux-gnu/ld-2.23.so 7fec9782f000-7fec97832000 rw-p 00000000 00:00 0 7fec97853000-7fec97854000 r--p 00025000 fc:01 1704106 /lib/x86_64-linux-gnu/ld-2.23.so 7fec97854000-7fec97855000 rw-p 00026000 fc:01 1704106 /lib/x86_64-linux-gnu/ld-2.23.so 7fec97855000-7fec97856000 rw-p 00000000 00:00 0 7ffe48e21000-7ffe48e42000 rw-p 00000000 00:00 0 [stack] 7ffe48f3e000-7ffe48f41000 r--p 00000000 00:00 0 [vvar] 7ffe48f41000-7ffe48f43000 r-xp 00000000 00:00 0 [vdso] ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall] jugbe@F-NAN-HIPPOPOTAME:~$
Remarque : La commande "pidof" renvoie le PID du processus donné en paramètre.
- Interpréter le fichier maps :
- Ligne 1 : 00400000-00401000 r-xp 00000000 fc:03 6562304 /home/jugbe/hello-smile est le segment texte de l'exécutable, en effet; on peut le reconnaître grâce à ses permissions (r = read, x = execute).
- Ligne 2 : 00600000-00601000 r--p 00000000 fc:03 6562304 /home/jugbe/hello-smile est la première partie du segment de données (permission : r=read).
- Ligne 3 : 00601000-00602000 rw-p 00001000 fc:03 6562304 /home/jugbe/hello-smile est la deuxième partie du segment de données (avec des autorisations de lecture et d'écriture).
- Ligne 4 : 00e1a000-00e3b000 rw-p 00000000 00:00 0 [heap] est le segment de tas (mémoire dynamique).
- Les lignes suivantes :
7fec97264000-7fec97424000 r-xp 00000000 fc:01 1704110 /lib/x86_64-linux-gnu/libc-2.23.so 7fec97424000-7fec97624000 ---p 001c0000 fc:01 1704110 /lib/x86_64-linux-gnu/libc-2.23.so 7fec97624000-7fec97628000 r--p 001c0000 fc:01 1704110 /lib/x86_64-linux-gnu/libc-2.23.so 7fec97628000-7fec9762a000 rw-p 001c4000 fc:01 1704110 /lib/x86_64-linux-gnu/libc-2.23.so
sont la bibliothèque C.
- Les lignes :
7fec9762e000-7fec97654000 r-xp 00000000 fc:01 1704106 /lib/x86_64-linux-gnu/ld-2.23.so 7fec97853000-7fec97854000 r--p 00025000 fc:01 1704106 /lib/x86_64-linux-gnu/ld-2.23.so 7fec97854000-7fec97855000 rw-p 00026000 fc:01 1704106 /lib/x86_64-linux-gnu/ld-2.23.so
est l'éditeur de liens dynamique.
- Le segment de la pile : 7ffe48e21000-7ffe48e42000 rw-p 00000000 00:00 0 [stack]
- La ligne : 7ffe48f41000-7ffe48f43000 r-xp 00000000 00:00 0 [vdso] (virtual dynamic shared object) qui permet d'exécuter certains appels système dans l'espace utilisateur
- Ligne : ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall] fait la même chose que "vdso" sur les architectures 32 bits (mais il est obsolète sur x86_64, il n'existe que pour la rétrocompatibilité).
Note : On remarquera que les bibliothèques sont chargées sur plusieurs segments car les permissions sont différentes (r-xp, ---p, r--p, ..., etc).
- L'exemple suivant hello-smile.c : affiche un message puis appelle la fonction pause().
- /proc/pid/pagemap : permet d'obtenir le mapping des pages (espace virtuel) vers les cadres dans la mémoire physique.
Attention : ce fichier est binaire, il faut le parser avec une application dédiée.Parser le fichier /proc/pid/pagemap
Il existe plusieurs façon de le faire, on peut utiliser le script écrit par JEFF LI
https://blog.jeffli.me/blog/2014/11/08/pagemap-interface-of-linux-explained/
Nous allons voir le mapping de la page 0x54adf000 vers la mémoire comme le montre la figure ci dessous.
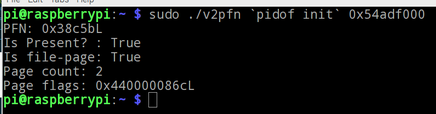
Le script parse le fichier pagemap et nous renvoi que la page est mappé vers le cadre mémoire 0x38c5bl (PFN = Page Frame Number). Le script parse aussi d'autres fichiers (/proc/kpagecount et /proc/kpageflags) pour nous renvoyer le nombre de références qui pointe vers le cadre mémoire et les flags associés.
- /proc/pid/limits : retourne les limites des processus en terme de ressources (Linux définit 16 ressources).
On peut voir les limites du processus "init" :$ cat /proc/1/limits Limit Soft Limit Hard Limit Units Max cpu time unlimited unlimited seconds Max file size unlimited unlimited bytes Max data size unlimited unlimited bytes Max stack size 8388608 unlimited bytes Max core file size 0 unlimited bytes Max resident set unlimited unlimited bytes Max processes 31583 31583 processes Max open files 1048576 1048576 files Max locked memory 65536 65536 bytes Max address space unlimited unlimited bytes Max file locks unlimited unlimited locks Max pending signals 31583 31583 signals Max msgqueue size 819200 819200 bytes Max nice priority 0 0 Max realtime priority 0 0 Max realtime timeout unlimited unlimited
Chaque processus peut utiliser un maximum de ressources définit dans Soft Limit. Si cela n'est pas suffisant, il peut augmenter jusqu'a la limite définit par Hard Limit.
Remarque : Seul les processus root peuvent augmenter leur Hard Limit, les processus conventionnels peuvent seulement la diminuer (le processus est irréversible). Aussi ne pas utiliser directement /proc/<pid>/limits pour réaliser ces ajustements, nous verrons la fonction setrlimit() plus loin dans cet article.
- /proc/pid/status : Informations sur le statut du processus.
Le système
L'autre partie exposée par le ProcFs est la configuration du système. Voici quelques exemples :
- /proc/meminfo : affiche l'état de la mémoire du système (ce fichier est parsé par les utilitaire free et vmstat).
- /proc/cpuinfo : renvoi les informations liées à chaque CPU.
SysFs
Le système de fichiers /proc n'a ni structure ni règles pour l'organiser. Les informations sont exposées d'une manière chaotique (les structures de données qui ne sont pas liées se trouvent au même endroit).
SysFs est un pseudo-système de fichiers structuré (http://man7.org/linux/man-pages/man5/sysfs.5.html).
Comme le but de l'article n'est pas le fichier /sys, un seul dossier nous intéresse c'est le : /sys/module (voir l'image ci-dessous). Ce dernier permet d'obtenir toutes les informations liées aux modules (Analyser le contenu de ce dossier est la première étape avant de commencer à déboguer un module).
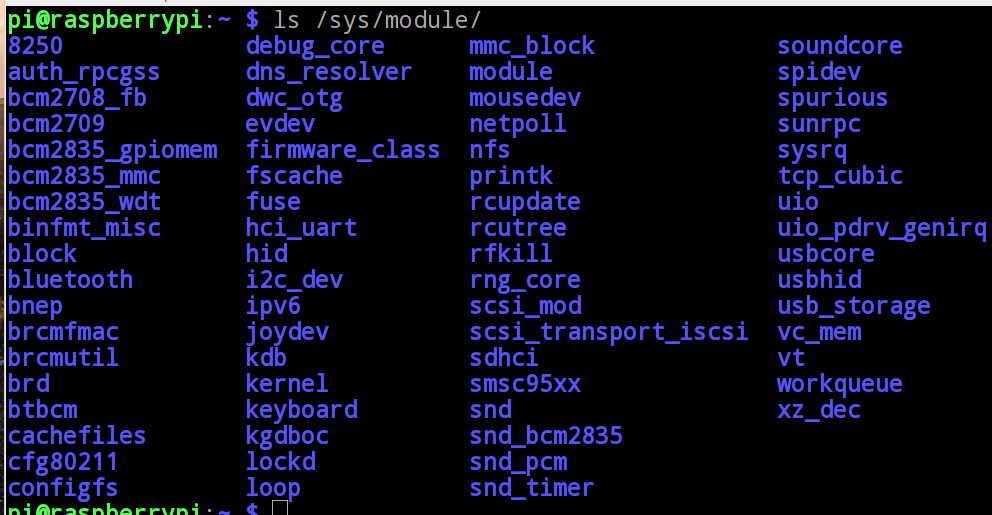
Remarque : La commande "lsmod" permet de lister les modules en cours d’exécution. Cette dernière est très utile pour vérifier si le module est bien chargé, sa taille et plus encore. Cependant, elle est très limité (on préfère utiliser le SysFS).
Les appels système et appels aux bibliothèques
Ptrace
Ptrace est le mécanisme le plus connu pour déboguer les applications de l'espace utilisateur.
La plupart des utilitaires de débogage (strace, ltrace et même GDB) s'appuient sur ptrace en arrière-plan (sans ce dernier ils seront inutiles).
En raison de problèmes de sécurité, certaines distributions comme Ubuntu désactivent ptrace par défaut. Dans ce cas, il faut l'activer comme suit:
$ sudo echo 0 > /proc/sys/kernel/yama/ptrace_scope
Une page détaillée sur Yama (patch de sécurité) est disponible sur ce lien : https://www.kernel.org/doc/Documentation/security/Yama.txt
Les appels système
L'appel système est la manière programmatique avec laquelle un programme demande un service au noyau.
strace est l'utilitaire qui permet de tracer les appels système
Nous allons apprendre à utiliser strace avec un exemple :
-
- Programme de test (file-reader.c) : Le programme suivant lit le contenu d'un fichier (disponible ici : https://github.com/jugurthab/Linux_kernel_debug/tree/master/debug-examples/Chap1-userland-debug/strace) :
#define FILE_PATH "smile-stats.txt" int main(int argc,char *argv[]){ FILE *fileDescriptorSmile=NULL; char c; fileDescriptorSmile = fopen(FILE_PATH,"r"); if(fileDescriptorSmile != NULL){ while (c != EOF){ printf ("%c", c); c = fgetc(fileDescriptorSmile); } printf("\n"); fclose(fileDescriptorSmile); } else { printf("Cannot open the file !\n"); } return EXIT_SUCCESS; } - Executer le programme : avec et sans traceur.
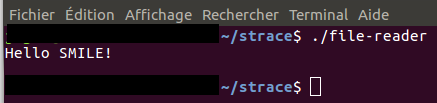
- Executer le programme sans strace : (voir l'image ci dessous)
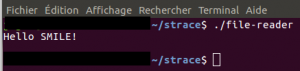
N.B : Le contenu du fichier a été bien lu.
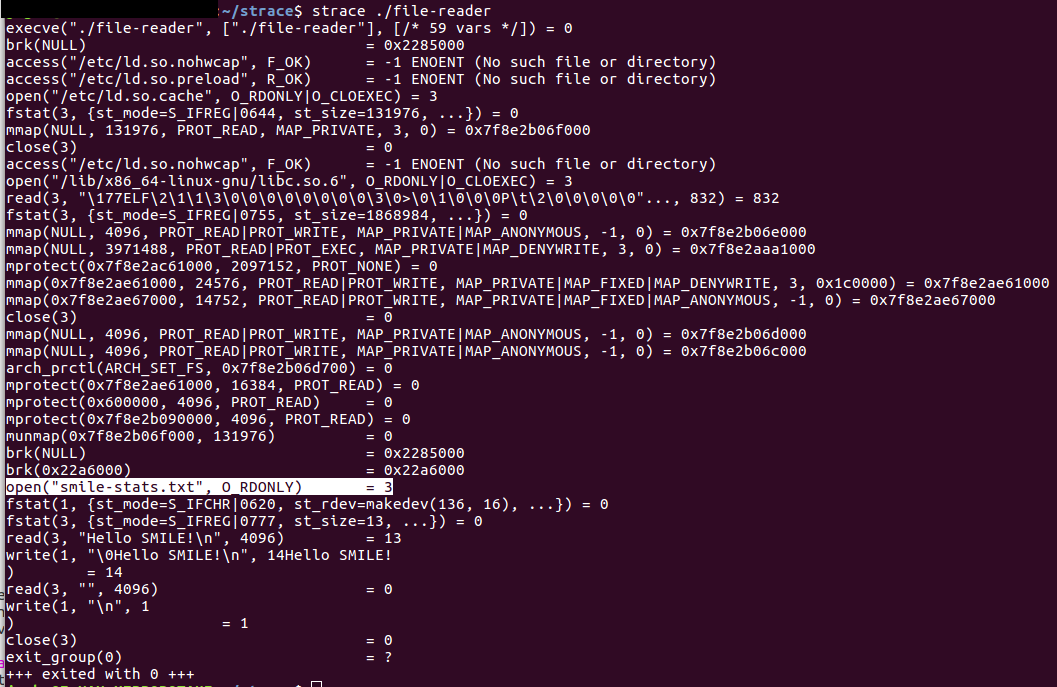
- Executer le programme avec strace (le fichier "file-reader" est présent dans le répertoire courant) : strace affiche (par défaut) tous les appels système (open, close, read, mmap, ..., etc).
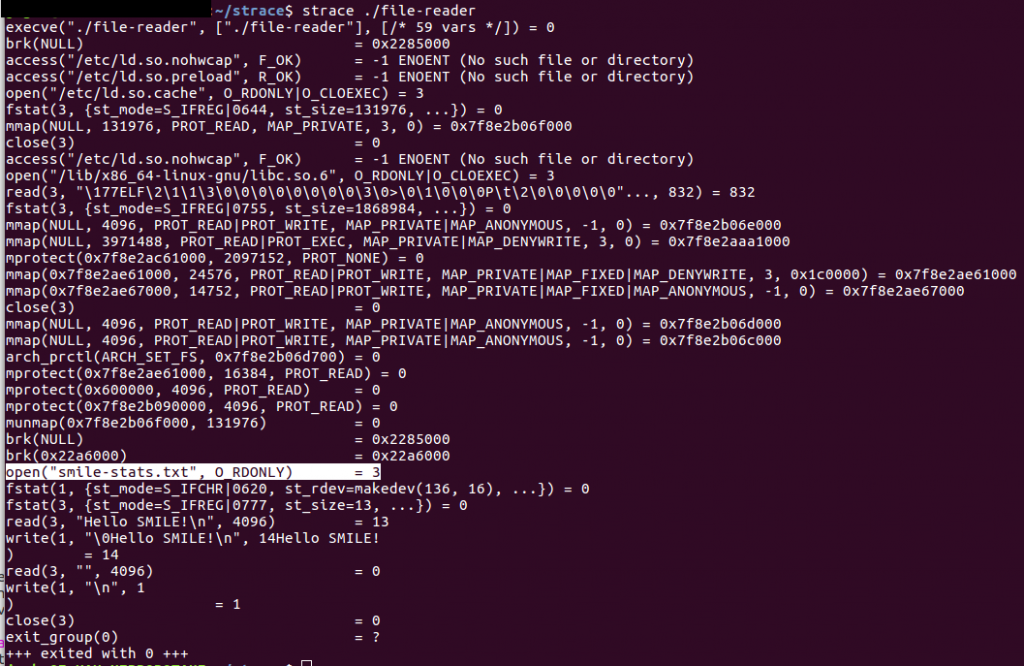
On voit clairement la ligne “open("smile-stats.txt", O_RDONLY) = 3”, cela veut dire dire que le fichier a été bien ouvert et l'appel système retourne le descripteur "3" pour le manipuler ultérieurement.
Mais pourquoi le descripteur est 3 et pas 1 ou 0
Par convention, chaque processus a au moins trois descripteurs de fichiers ouverts : 0 (stdin), 1 (stdout) et 2 (stderr). Ce qui fait que le prochain descripteur qu'un processus peut ouvrir est 3.
- Executer le program avec strace (le fichier "file-reader" est absent du répertoire courant) : nous allons essayer de supprimer le fichier "smile-stats.txt" de son emplacement puis d'appliquer strace sur notre programme (voir l'image ci-dessous).
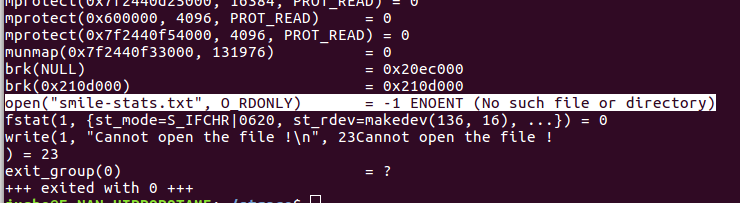
Cette fois ci, strace retourne -1 (descripteur de fichier invalide), et affiche la raison de l’échec (fichier ou dossier introuvable).
- Executer le programme sans strace : (voir l'image ci dessous)
- Quelques options utiles de strace :
- Sélectionner les appels système à tracer
$ strace -e trace=SysCall1, SysCall2, SysCall3 ./monProgram -
Sélectionner les types d'appels système à tracer
$ strace -e open,close ./monProgramPar exemple :
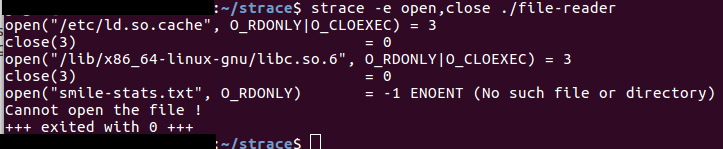
- Filtrer les appels système par catégories : le rapport de strace peut rapidement devenir trop grand, on peut filtrer par catégorie :
System call Categories Related system calls file open, chmod, stat, truncate, ...,etc. process Process management : clone, exit_group, execve, wait4, ..., etc. network Network syscalls : socket, linsten, bind, ..., etc. memory mmap, mprotect, ..., etc Pour récupérer les appels système liés a la manipulation de fichiers, nous devons utiliser l'option suivante :
$ strace -e trace=file ./file-reader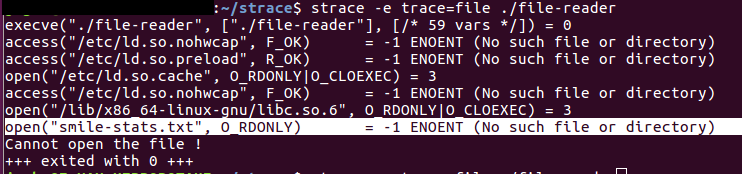
On peut tracer plusieurs catégories, pour tracer les appels système liés aux fichiers et à la mémoire :
$ strace -e trace=file,memory ./file-reader - Sauvegarder la trace dans un fichier : on peut rediriger le rapport de strace vers un fichier.
$ strace -o fichier ./file-readerPar exemple, pour récupérer les appels système fstat et les sauvegarder dans un fichier (log.txt) :
$ strace -o log.txt -e fstat ./file-reader
- Sélectionner les appels système à tracer
- Programme de test (file-reader.c) : Le programme suivant lit le contenu d'un fichier (disponible ici : https://github.com/jugurthab/Linux_kernel_debug/tree/master/debug-examples/Chap1-userland-debug/strace) :
Le secret de la commande "free" ?
Nous allons découvrir l'origine des informations fournis par free avec strace :
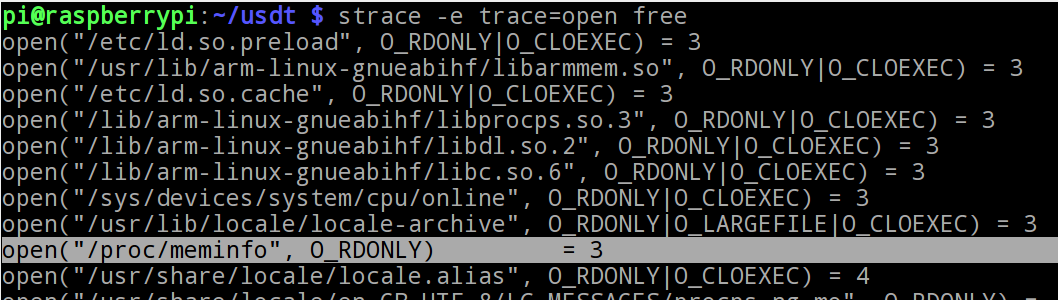
free parse le fichier /proc/meminfo
Les appels aux bibliothèques
Les programmes font appel à des fonctions se trouvant dans des bibliothèques partagées. Et cela signifie simplement que le chemin d'une bibliothèque est recherché au moment de l'exécution pour déterminer l'emplacement de la fonction à appeler. Ces appels ne sont pas en destination du noyau (ne peuvent pas être tracé pas strace).
ltrace est l'utilitaire qui permet de tracer les appels entre un exécutable et des bibliothèques
Pour illustrer le fonctionnement de ltrace, nous allons créer notre propre bibliothèque :
- Création de la bibliothèque : notre bibliothèque va définir une fonction "helloOpenSource" qui affiche un message passé en argument (Les sources sont aussi disponible sur : https://github.com/jugurthab/Linux_kernel_debug/tree/master/debug-examples/Chap1-userland-debug/ltrace).
- smile-hello-open-source.h : fichier entête de la bibliothèque.
void helloOpenSource(const char *message);
- smile-hello-open-source.cpp : fichier source qui contient l'implémentation de la fonction définit dans smile-hello-open-source.h.
void helloOpenSource(const char *message){ printf("%s",message); } - Compilation de la bibliothèque : (voir ci-dessous)
$ gcc -fPIC --shared -o libsmile-hello-open-source.so smile-hello-open-source.cpp
- smile-hello-open-source.h : fichier entête de la bibliothèque.
- Le programme de test (ltrace-hello.cpp) :
#include "smile-hello-open-source.h" int main(){ helloOpenSource("The world is better when source code is open!\n"); return EXIT_SUCCESS; } - Lier la bibliothèque avec le programme de test : nous devons compiler notre programme avec la bibliothèque :
$ export LD_LIBRARY_PATH=.
$ gcc -o ltrace-hello ltrace-hello.cpp -lsmile-hello-open-source -L.

- Tester le programme : avant d'utiliser ltrace, nous allons nous assurer que le programme est bien compilé.
- Vérifier si la bibliothèque est bien attaché à l'exécutable.

On voit bien que libsmile-hello-open-source.so possède un chemin valide (./libsmile-hello-open-source.so).
- Executer le programme : Nous pouvons exécuter le programme a présent :

- Vérifier si la bibliothèque est bien attaché à l'exécutable.
- Tracer les appels à la bibliothèque avec ltrace : nous allons enfin utiliser ltrace. Commençons par l'installer (si il n'est pas déjà présent) :
$ sudo apt-get install ltracePuis on peut lancer ltrace avec notre programme comme ceci :

ltrace a capturé l'appel de la fonction main (__libc_start_main de notre programme) vers la fonction helloOpenSource (qui se trouve dans notre bibliothèque).
Limitations de ltrace
ltrace capture tous les appels entre un exécutable et des bibliothèques. Cependant; il ne peut pas suivre les appels entre les bibliothèques (d'ailleurs notre fonction helloOpenSource fait appel à la fonction printf qui se trouve dans la bibliothèque C).
- Tracer même les appels entre bibliothèques : comme ltrace devient vite limité, latrace est la solution à notre problème.
$ sudo apt-get install latraceNous allons appliquer latrace sur notre programme :
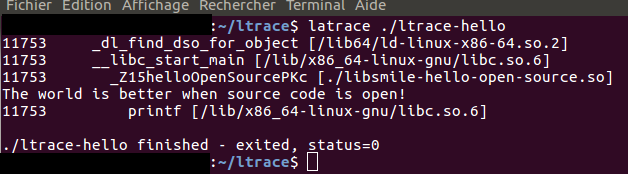
on voit bien : __libc_start_main qui appelle helloOpenSource et qui elle même appelle printf.
latrace affiche les appels sous forme d'un arbre, on peut facilement voir la relation entre les appels.
N.B : Il est aussi important de rappeler que ltrace ou latrace ne peuvent pas suivre les fonctions si l'executable inclut statiquement les bibliothèques partagées (compilation sans le paramètre -static avec gcc) et les fonctions ne doivent pas être déclaré avec l'attribut inline (certains compilateurs utilisent la technologie Link-Time Code Generation qui peux mettre les fonctions en mode inline même si elles ne sont pas déclarées de la sorte), en outre les symboles des fonctions doivent apparaitre avec l'utilitaire nm.
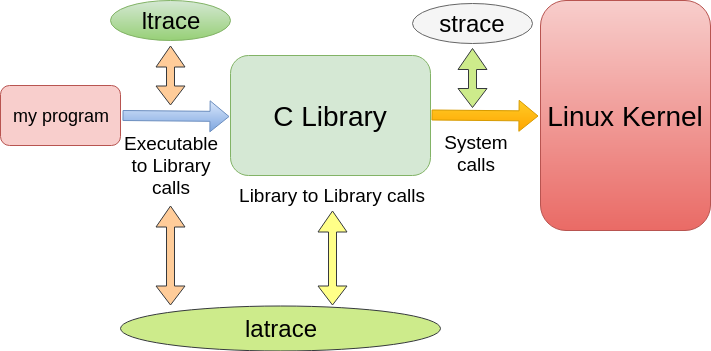
Pour finir, voici une image qui récapitule les outils nécessaires pour tracer différents appels :
Chasse aux erreurs avec Valgrind
Valgrind est un framework de débogage, d'intrumentation et de profilage de mémoire pour les applications de l'espace utilisateur.
Les sources des démos
Les sources sont disponibles sur le lien suivant :
https://github.com/jugurthab/Linux_kernel_debug/tree/master/debug-examples/Chap1-userland-debug/valgrind
Le framework Valgrind propose plusieurs outils; Memcheck, Cachegrind, Callgrind, Massif, Helgrind, DRD, etc.
Memcheck
C'est l'outil le plus connu sous Valgrind, memcheck est un détecteur d'erreur mémoire. Il permet de traquer les problèmes suivant :
- Les fuites mémoire : Le code suivant sera utilisé comme exemple :
int main(){ char *str; str = (char*)calloc(40, sizeof(char)); // Try to avoid malloc // do not use memset after malloc (use calloc) return EXIT_SUCCESS; }Nous pouvons l'analyser avec memcheck comme suit :
pi@raspberrypi:~/userspace/valgrind/memcheck$ gcc memcheck-memory-leak.c -o memcheck-memory-leak -g pi@raspberrypi:~/userspace/valgrind/memcheck$ valgrind --tool=memcheck --leak-check=full ./memcheck-memory-leak ==7369== Memcheck, a memory error detector ........................ ==7369== Command: ./memcheck-memory-leak ==7369== ==7369== ==7369== HEAP SUMMARY: ==7369== in use at exit: 40 bytes in 1 blocks ==7369== total heap usage: 1 allocs, 0 frees, 40 bytes allocated ==7369== ==7369== 40 bytes in 1 blocks are definitely lost in loss record 1 of 1 ==7369== at 0x4C2FB55: calloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so) ==7369== by 0x40053C: main (memcheck-memory-leak.c:8) ==7369== ........................ ........................
Memcheck a détecté la fuite mémoire (40 bytes in 1 blocks are definitely lost in loss record 1 of 1) et pointe vers son emplacement (by 0x40053C: main (memcheck-memory-leak.c:8)).
- Les variables non initialisées : Une illustration de l'outil peut se faire comme suit :
int main(){ int loveOpenSource; if(loveOpenSource) printf("Welcome to SMILE!\n"); else printf("Let's change your mind!\n"); return EXIT_SUCCESS; }On peut essayer d'appliquer memcheck sur l'executable :
pi@raspberrypi:~/userspace/valgrind/memcheck$ gcc memcheck-uninitialized-variable.c -o memcheck-uninitialized-variable -g pi@raspberrypi:~/userspace/valgrind/memcheck$ valgrind --tool=memcheck ./memcheck-uninitialized-variable ........................ ==7594== Command: ./memcheck-uninitialized-variable ==7594== ==7594== Conditional jump or move depends on uninitialised value(s) ==7594== at 0x400532: main (memcheck-uninitialized-variable.c:8) ==7594== Let's change your mind! ==7594== ........................ ........................
memcheck signale le jump conditionnel (main (memcheck-uninitialized-variable.c:8)) qui dépend d'une variable non-initialisée.
- Les fonctions d'allocation et de désallocation en discordance : L'allocation en C est différente du C++ (en effet le dernier retroune un objet et pas seulement une adresse), il arrive parfois que leurs syntaxes se chevauchent (surtout qu'on travaille en équipe) comme ceci :
int main(){ int *nbElements = NULL; nbElements = (int *) calloc(20, sizeof(int)); delete(nbElements); // Use C++ delete return EXIT_SUCCESS; }Memcheck peut facilement détecter ce genre de problème.
pi@raspberrypi:~/userspace/valgrind/memcheck$ g++ memcheck-mismatch-alloc-free.c -o memcheck-mismatch-alloc-free -g pi@raspberrypi:~/userspace/valgrind/memcheck$ valgrind --tool=memcheck ./memcheck-mismatch-alloc-free ........................ ==7896== Mismatched free() / delete / delete [] ==7896== at 0x4C2F24B: operator delete(void*) (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so) ==7896== by 0x400674: main (memcheck-mismatch-alloc-free.c:9) ==7896== Address 0x5ab6c80 is 0 bytes inside a block of size 80 alloc'd ==7896== at 0x4C2FB55: calloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so) ==7896== by 0x400664: main (memcheck-mismatch-alloc-free.c:7) ==7896== ........................ ........................
On voit clairement que la faute se trouve dans “memcheck-mismatch-alloc-free.c:9” et “memcheck-mismatch-alloc-free.c:7”.
- Lire (ou écrire) à la fin d'un tampon mémoire : c'est une source d'erreur très commune comme on peut l'illustrer :
int main(){ char *str; str = (char *) calloc(10, sizeof(char)); printf("%c\n", *(str+20)); free(str); return EXIT_SUCCESS; }Memcheck est encore capable de traquer ces erreurs :
pi@raspberrypi:~/userspace/valgrind/memcheck$ gcc memcheck-read-over-buffer.c -o memcheck-read-over-buffer -g pi@raspberrypi:~/userspace/valgrind/memcheck$ valgrind --tool=memcheck ./memcheck-read-over-buffer ........................ ==8037== Command: ./memcheck-read-over-buffer ==8037== ==8037== Invalid read of size 1 ==8037== at 0x4005D9: main (memcheck-read-over-buffer.c:10) ==8037== Address 0x5204054 is 10 bytes after a block of size 10 alloc'd ==8037== at 0x4C2FB55: calloc (in /usr/lib/valgrind/vgpreload_memcheck-amd64-linux.so) ==8037== by 0x4005CC: main (memcheck-read-over-buffer.c:8) ==8037== ........................ ........................
Helgrind
Helgrind détecte les erreurs de synchronisation dans les programmes C/C++ et Fortran qui utilisent les primitives de threading POSIX pthreads.
Une démo sera plus parlante :
Les sources de la démo
Un exemple de threads qui calculent un produit scalaire est fourni sur le lien suivant :
https://github.com/jugurthab/Linux_kernel_debug/tree/master/debug-examples/Chap1-userland-debug/valgrind/helgrind
On peut l'analyser avec helgrind comme suit :
$ gcc helgrind-threads-file-writer.c -o helgrind-threads-file-writer -pthread -g $ valgrind --tool=helgrind ./helgrind-threads-file-writer ==15238== Possible data race during read of size 4 at 0x601084 by thread #3 ==15238== Locks held: none ==15238== at 0x40084B: writeToSharedVariable (helgrind-threads-file-writer.c:14) ==15238== by 0x4C34DB6: ??? (in /usr/lib/valgrind/vgpreload_helgrind-amd64-linux.so) ==15238== by 0x4E476B9: start_thread (pthread_create.c:333) ==15238== ==15238== This conflicts with a previous write of size 4 by thread #2 ==15238== Locks held: none ==15238== at 0x400845: writeToSharedVariable (helgrind-threads-file-writer.c:15) ==15238== by 0x4C34DB6: ??? (in /usr/lib/valgrind/vgpreload_helgrind-amd64-linux.so) ==15238== by 0x4E476B9: start_thread (pthread_create.c:333) ==15238== Address 0x601084 is 0 bytes inside data symbol "sharedVariable"
Callgrind
Callgrind est un profileur CPU. Le lecteur est probablement familier avec GPROF. ce dernier est devenu obsolète car il ne supporte pas les threads et ne sait pas interpréter les appels système.
Un exemple sera mieux :
Les sources de la démo
Un exemple de générateur de nombre pseudo-aléatoire est disponible sur le lien suivant :
https://github.com/jugurthab/Linux_kernel_debug/blob/master/debug-examples/Chap1-userland-debug/valgrind/callgrind/callgrind-test.c
Scanner son code avec callgrind se fait en deux étapes :
- Sauvegarder le profilage de code dans un fichier :
pi@raspberrypi:~/userspace/valgrind/callgrind$ gcc callgrind-cpu-profile.c -o callgrind-cpu-profile -g pi@raspberrypi:~/userspace/valgrind/callgrind$ valgrind --tool=callgrind ./callgrind-cpu-profile ==6886== Callgrind, a call-graph generating cache profiler ==6886== Copyright (C) 2002-2015, and GNU GPL'd, by Josef Weidendorfer et al. ==6886== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info ==6886== Command: ./callgrind-cpu-profile ==6886== ==6886== For interactive control, run 'callgrind_control -h'. ==6886== ==6886== Events : Ir ==6886== Collected : 183388 ==6886== ==6886== I refs: 183,388
Callgrind signale qu'il a recueilli 183388 événements.
- Lire le fichier profilage : La lecture se fait avec la commande suivante :
$ callgrind_annotate −−auto=yes callgrind.out.pid. #define NUMBER_IN_SET 500 . #define MAX_NUMBER_VALUE 100 . #define MIN_NUMBER_VALUE 2 . . int generateRandomNumber(); . 6 int main(){ . . int numberSet1[NUMBER_IN_SET], numberSet2[NUMBER_IN_SET], i; . int totalSet[NUMBER_IN_SET]; 14 srand(time(NULL)); 12,286 => /build/glibc-Cl5G7W/glibc-2.23/elf/../sysdeps/x86_64/dl-trampoline.h:_dl_runtime_resolve_avx'2 (2x) . 1,504 for(i=0; i<NUMBER_IN_SET; i++){ 3,000 numberSet1[i] = generateRandomNumber(); 33,833 => callgrind-cpu-profile.c:generateRandomNumber (500x) 3,000 numberSet2[i] = generateRandomNumber(); 32,984 => callgrind-cpu-profile.c:generateRandomNumber (500x) . // add the 2 generated numbers and store them 5,000 totalSet[i] = numberSet1[i] + numberSet2[i]; . } . 1 return EXIT_SUCCESS; 5 } . /* Function that generates a random integer */ 2,000 int generateRandomNumber(){ 15,004 return (rand() % (MAX_NUMBER_VALUE - MIN_NUMBER_VALUE)) + MIN_NUMBER_VALUE; 46,921 => /build/glibc-Cl5G7W/glibc-2.23/stdlib/rand.c:rand (999x) 892 => /build/glibc-Cl5G7W/glibc-2.23/elf/../sysdeps/x86_64/dl-trampoline.h:_dl_runtime_resolve_avx'2 (1x) 2,000 }Callgrind affiche le nombre d'instructions (assembleur) dans le code source.
Cachegrind
Cachegrind simule comment notre programme interagit avec la hiérarchie de cache d'une machine.
Les sources de la démo
Le code de l'exemple suivant écrit une structure dans un fichier binaire puis le relit et sauvegarde son contenu dans une autre structure :
https://github.com/jugurthab/Linux_kernel_debug/tree/master/debug-examples/Chap1-userland-debug/valgrind/cachegrind
Cachegrind peut mettre en évidence les échanges avec les caches, ce qui peut aider dans l'optimisation.
pi@raspberrypi:~/userspace/valgrind/cachegrind$ valgrind --tool=cachegrind ./cachegrind-cache-stats ==7153== Cachegrind, a cache and branch-prediction profiler ==7153== Copyright (C) 2002-2015, and GNU GPL'd, by Nicholas Nethercote et al. ==7153== Using Valgrind-3.11.0 and LibVEX; rerun with -h for copyright info ==7153== Command: ./cachegrind-cache-stats ==7153== --7153-- warning: L3 cache found, using its data for the LL simulation. ----- The new content of structure employeeInfoInput ------ Name : Jugurtha BELKALEM Age : 26 ==7153== ==7153== I refs: 164,821 ==7153== I1 misses: 1,114 ==7153== LLi misses: 1,097 ==7153== I1 miss rate: 0.68% ==7153== LLi miss rate: 0.67% ==7153== ==7153== D refs: 55,056 (41,954 rd + 13,102 wr) ==7153== D1 misses: 3,011 ( 2,437 rd + 574 wr) ==7153== LLd misses: 2,481 ( 1,963 rd + 518 wr) ==7153== D1 miss rate: 5.5% ( 5.8% + 4.4% ) ==7153== LLd miss rate: 4.5% ( 4.7% + 4.0% ) ==7153== ==7153== LL refs: 4,125 ( 3,551 rd + 574 wr) ==7153== LL misses: 3,578 ( 3,060 rd + 518 wr) ==7153== LL miss rate: 1.6% ( 1.5% + 4.0% )
Ou I = Instruction et D = Données.
Important : Cachegrind simule toujours deux niveaux de caches (même si votre machine en possède plus). Pour éviter les ambiguités LL veut dire (Last level), qui peut être interprété comme le dernier cache (ce qui veut dire : I1, D1 représent le premier cache et LLi, LLd le dernier).
Après ce petit exemple, nous laissons le lecteur prolonger l'étude de ces profilers par lui-même.
Nous en avons terminé avec ce survol de Valgrind, nous présentons maintenant ce qu'est un fichier "core".
Fichiers core
C'est un fichier contenant l'espace d'adresse mémoire d'un processus lorsque ce dernier se termine de façon inattendue.
Un exemple d'erreur classique consiste à référencer une adresse nulle (qui n'existe pas) comme suit :
int main(){
*(int *)NULL = 0; // dereferencing NULL pointer
printf("SMILE, This is a dereferenced NULL pointer!!\n");
return EXIT_SUCCESS;
}
Nous allons compiler le programme et le lancer comme suit:
pi@raspberrypi:~/debugUserSpace/core-dump $ ls userland-core-dump-analysis.c pi@raspberrypi:~/debugUserSpace/core-dump $ gcc userland-core-dump-analysis.c -o userland-core-dump-analysis -g pi@raspberrypi:~/debugUserSpace/core-dump $ ./userland-core-dump-analysis Segmentation fault pi@raspberrypi:~/debugUserSpace/core-dump $ ls userland-core-dump-analysis userland-core-dump-analysis.c pi@raspberrypi:~/debugUserSpace/core-dump $
Problème : Mais pourquoi le fichier dump n'est pas généré?
- Activer les fichiers dump : Les fichiers dump ne sont plus générés par défaut lorsqu'on installe un système. La majorité des utilisateurs ne savent pas les utiliser, et souvent prennent de la place. Les linuxiens ont décidé de les désactiver. Nous pouvons voir la configuration ressources associée a chaque utilisateur comme ci-dessous :
pi@raspberrypi:~/debugUserSpace/core-dump $ ulimit -a core file size (blocks, -c) 0 data seg size (kbytes, -d) unlimited scheduling priority (-e) 0 file size (blocks, -f) unlimited pending signals (-i) 7336 max locked memory (kbytes, -l) unlimited max memory size (kbytes, -m) unlimited open files (-n) 65536 pipe size (512 bytes, -p) 8 POSIX message queues (bytes, -q) 819200 real-time priority (-r) 95 stack size (kbytes, -s) 8192 cpu time (seconds, -t) unlimited max user processes (-u) 7336 virtual memory (kbytes, -v) unlimited file locks (-x) unlimited pi@raspberrypi:~/debugUserSpace/core-dump $
La ligne : "core file size : (blocks, -c) 0" représente la taille du fichier dump qui sera généré. Dans ce cas, 0 veut dire aucun fichier ne sera généré. Pour corriger ce problème, il suffit de saisir la commande suivante :
$ ulimit -c unlimited - Récupérer le fichier dump : Maintenant, il suffit de lancer notre programme et le fichier dump sera écrit si une erreur survient comme montré ci-dessous.
pi@raspberrypi:~/debugUserSpace/core-dump $ ls userland-core-dump-analysis.c pi@raspberrypi:~/debugUserSpace/core-dump $ ulimit -c unlimited pi@raspberrypi:~/debugUserSpace/core-dump $ gcc userland-core-dump-analysis.c -o userland-core-dump-analysis -g pi@raspberrypi:~/debugUserSpace/core-dump $ ./userland-core-dump-analysis Segmentation fault (core dumped) pi@raspberrypi:~/debugUserSpace/core-dump $ ls core userland-core-dump-analysis userland-core-dump-analysis.c pi@raspberrypi:~/debugUserSpace/core-dump $
- Lire le fichier dump : Le fichier dump peut être lu avec gdb :
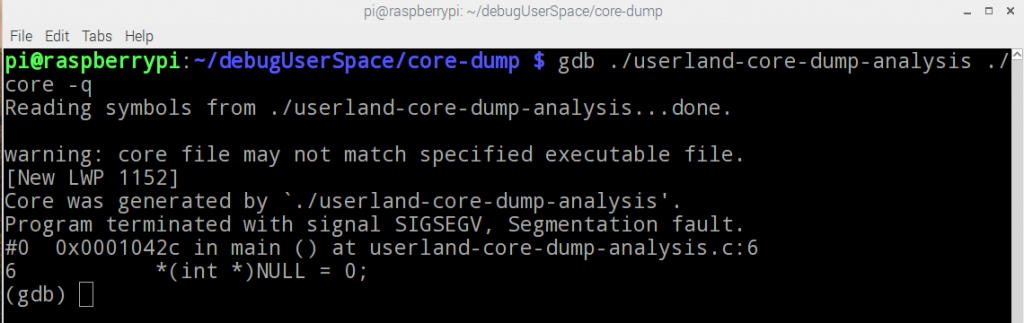
GDB indique que le problème se trouve dans la ligne 6 (*(int *)NULL = 0 ) qui correspond a notre erreur.
Attention : GDB a besoin de la table des symboles, il faut toujours les inclures lors de la compilation (gcc -g)
Activer les fichiers dump programmatiquement
On peut changer les ressources logicielles d'un processus programmatiquement (seul root peut augmenter ses ressouces materiels). La structure concernée est “struct rlimit”.
int main(){ struct rlimit rlimProcess; // declare resource structure int returnValue; rlimProcess.rlim_cur = RLIM_INFINITY; // Set software resource limits to unlimited rlimProcess.rlim_max = RLIM_INFINITY; // Set hardware resource limits to unlimited returnValue = setrlimit (RLIMIT_CORE, &rlimProcess); // Change core dump size to unlimited if (returnValue == -1){ perror("setlimit Error "); exit(EXIT_FAILURE); } int testOverflow[10]; testOverflow[11] = 60; // OVERFLOW because location does not exist return EXIT_SUCCESS; }
Débogage coté noyau
Le débogage noyau est différent de l'espace utilisateur, voici quelques méthodes qui permettent de le faire :

Dans cet article, nous verrons les fautes systèmes et comment déboguer des modules avec KGDB/KDB.
Fautes système
Les fautes système ne désignent pas un Kernel Panic, ce dernier est le résultat d'une faute grave ou d'un effet en cascade de fautes système.
Lorsqu'un programme en espace utilisateur viole un accès mémoire, un SIGSEGV est généré et le processus défectueux est détruit (n'oubliez pas d'activer les fichiers core dump pour les analyser). La même chose est vraie pour le noyau, lorsqu'un driver (ou module) essaie de "déréférencer un pointeur nul invalide" ou "déborde le tampon de destination", il va être tué.
Si le Kernel Panic ne se manifeste pas (à cause d'un erreur grave), le code défectueux dans un pilote ou un module peut conduire à l'un des états kernel oops, kernel hang.
Kernel Oops
Parfois appelé panique douce (par opposition à panique kernel). Généralement, c'est le résultat d'un déréférencement vers un pointeur nul. Dans ce cas le noyau écrit des messages d'erreurs appelés oops dans son tampon.
Module défectueux
Sources de l'exemple
Un module défectueux est disponible sur : https://github.com/jugurthab/Linux_kernel_debug/tree/master/debug-examples/Chap2-kernel-debug/kernel-oops
- Le code du module : le module fait un déréférencement vers un pointeur nul.
static void createOops(void){ *(int *)0 =0; } static int __init initializeModule(void){ printk("Hey SMILE!This is a kernel oops test module!!!\n"); createOops(); return 0; } static void __exit cleanModule(void){ printk("Goodby SMILE! Module exited!\n"); } module_init(initializeModule); module_exit(cleanModule); - Création du Makefile : pour compiler le module.
obj-m += kernel-oops-mod.o MY_CFLAGS += -g -DDEBUG ccflags-y += ${MY_CFLAGS} CC += $(MY_CFLAGS) default: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules debug: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules EXTRA_CFLAGS="$(MY_CFLAGS)" clean: make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean - Compiler le module :
$ make debug - Insérer le module dans le noyau :

Comprendre les oops
Nous pouvons lire du tampon noyau les messages oops avec la commande dmesg : $ dmesg
Pleins de messages s’afficheront dont la majorité ne sont pas des oops (mais plutôt un rapport du système).
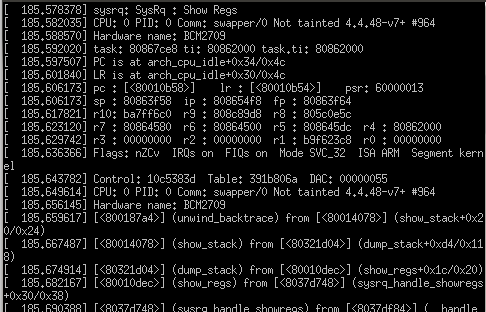
- Récupérer les oops : La première ligne de l'erreur est la plus importante comme illustré ci dessous :

- BUG : désigne le type de l'erreur.
- IP (Instruction Pointer) : indique l'emplacement de l'erreur (nous y reviendrons plus tard).
- Interprétation du code oops :

Nous pouvons regarder de plus près le code d'erreur 0002. Le nombre est en décimal, nous devons le convertir en binaire:
0002 (décimal) = 0010 (binaire)
Pour comprendre la signification du code, il faut voir le schéma suivant :
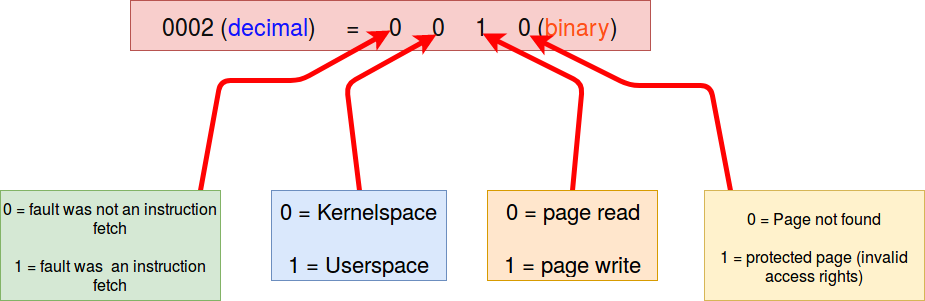
Maintenant on est capable de lire le code :
0 0 0 0 1 = la faute est le résultat d'un accès en écriture à une page inexistante dans l'espace noyau, cependant l'instruction n'est pas une instruction fetch.
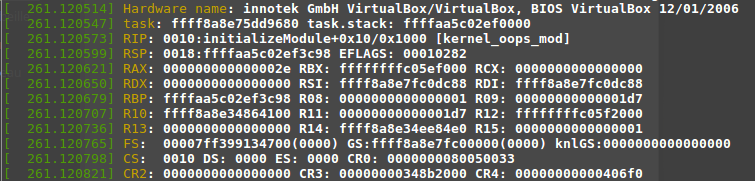
- Contenu des registres : on peut jeter un coup d’œil sur l'état des registres.
- Contenu de la trace : peut être intéressante.
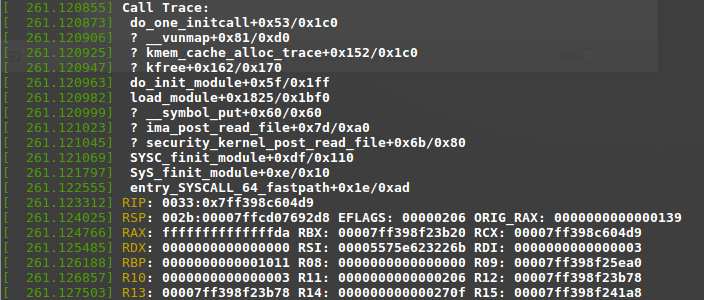
Remarque : Le ? présent a coté de certaines fonctions signifie que les informations sur cette entrée ne sont probablement pas fiables (voir https://stackoverflow.com/questions/13113384/what-is-the-meaning-of-question-marks-in-linux-kernel-panic-call-traces).
- Instruction en cours d'exécution : Le code machine de l'instruction en cours d’exécution est affiché.

Nous ne décortiquerons pas ce code machine, nous laisson le lecteur motivé s'en occuper.
- Registre IP : Nous allons enfin apprendre à lire la signification du registre RIP.
IP : fonction + offset/taille_fonction
Cela veut dire que la fonction "initializeModule" est d'une taille de 0x1000 et l'erreur se produit à l'offset 0x10 (par rapport au début de la fonction).
- Adresse du module :

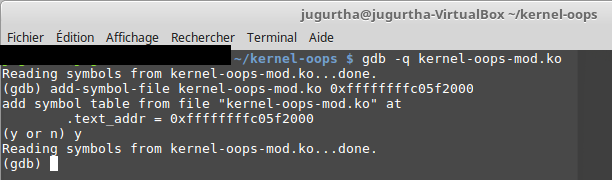
- Lancer une session GDB : démarrer une session GDB, ajouter à GDB l'emplacement du module comme indiqué ci dessous :
- L'assembleur entre en jeu : Nous devons désassembler la fonction qui a conduit à l'erreur. La fonction "initializeModule" commence à : 0x0000000000000024. Le registre IP a rapporté que le mauvais code est à 0x10 du début de cette fonction, donc l'erreur se trouve ci-dessous :
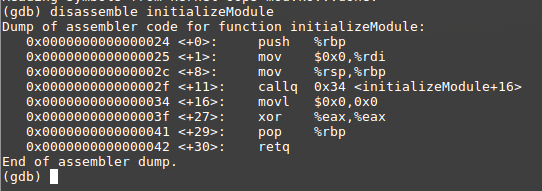
0x0000000000000024 + 0x10 = 0x0000000000000034 = movl $0x0, 0x0 - Localiser la ligne de code erronée : enfin, jetons un coup d'oeil à cette ligne avec GDB :
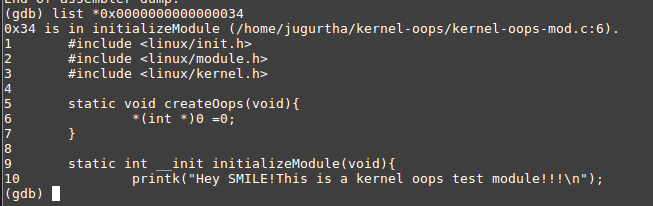
GDB pointe vers la ligne /kernel-oops-mod.c :6 qui est à l'origine du problème.
Touches Magique SysRQ
Il peut arriver que les systèmes se figent (par exemple l'interface graphique qui ne répond plus). Dans ce cas, le réflexe adopté est de redémarrer la machine. Cela peut avoir de lourdes conséquences, en effet, les fichiers ne sont pas synchronisés avec le disque.
Les touches magique SysRq permettent d’exécuter des fonctions de bas niveau avec une combinaison de touches comme suit :
ALT + touche Imp écran (SysRq) + touche commande
Ces touches peuvent aussi renvoyer la liste des processus en cours d’exécution, l’état des CPU, la trace inverse qu'on peut récupérer par voix série. Cependant, cette fonctionnalité peut être désactivée, si c'est le cas il faut l'activer :
# echo 1 > /proc/sys/kernel/sysrq
Quelques touches à retenir :
- ALT + touche Imp écran (SysRq) + chiffre : pour changer la verbosité (ALT+SysRq+9 est le maximum).

Remarque : changer le niveau de verbosité est la première chose à faire avant de déboger.
- ALT + touche Imp écran (SysRq) + l : affiche la trace inverse de tous les CPU.
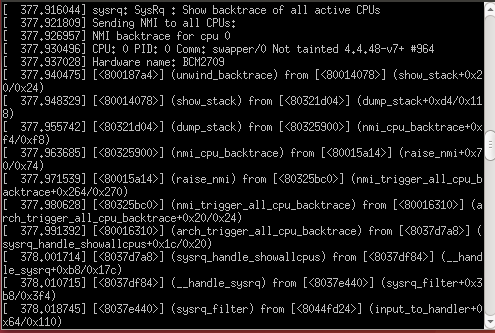
- ALT + touche Imp écran (SysRq) + m : dumper la mémoire virtuelle.
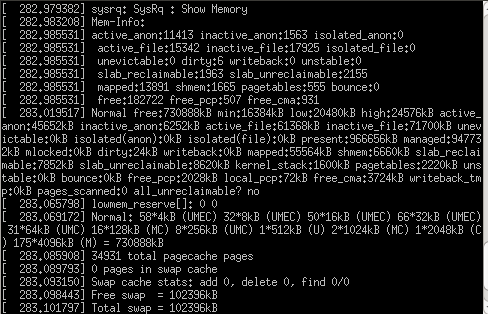
- ALT + touche Imp écran (SysRq) + p : retourne l'état des registres.
- ALT + touche Imp écran (SysRq) + c : génération d'un Kernel PANIC (très utile pour les tests).
Au secours des Modules
Les modules peuvent être difficiles à déboguer, une configuration est requise avant de pouvoir les déboguer avec GDB. Le problème provient du code relogeable du module, ce qui signifie que l'adresse du module est décidée au moment du chargement. Sous Linux, nous pouvons obtenir l'emplacement du module en utilisant l'interface sysfs. Les développeurs doivent lire l'emplacement de chaque section de :
/sys/module/nom_du_module/sections
- Code module : Les sources sont disponible sur https://github.com/jugurthab/Linux_kernel_debug/tree/master/debug-examples/Chap2-kernel-debug/debug-module
- Compilation du module :
$ make - Insérer le module dans le noyau :
$ sudo insmod basic-module-debug.ko - Récupérer le nombre majeur : il faut lire les messages du tampon
$ dmesg(voir l'image ci-dessous).

- Créer une entrée dans /dev :

- Vérifiez le bon fonctionnement du module :
- Interagir avec le module :
# cat /dev/basictestdriver - Vérifier les messages du tampon noyau :

- Interagir avec le module :
- Obtenir la localisation du module en mémoire :

- Établir une communication série avec la cible.
- Configurer KGDB : il faut activer KGDB/KDB sur la cible (la console à droite de l'image ci-dessous) et GDB sur une autre machine (la console à gauche de l'image ci-dessous).

- Déboguer le module : A présent, nous pouvons déboguer comme on a l'habitude de faire avec GDB. on peut par exemple :
- Obtenir l'adresse des fonctions du module :
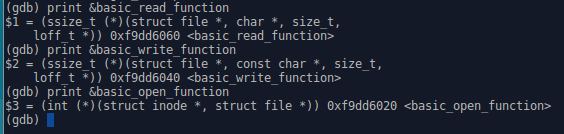
- Positionner des points d'arrêt :

- Reprendre l'exécution sur la cible : il suffit de taper "c" dans GDB :

- Obtenir l'adresse des fonctions du module :

Débogage JTAG
C'est la méthode de débogage la plus puissante (mais la plus complexe) car, à la différence des autres solutions (qui sont purement logiciel), c'est un débogage au niveau matériel (JTAG, SWD et autres).
OpenOCD est une solution Open Source qui nous permet de mener un débogage matériel, un article entier lui a été réservé sur : http://www.linuxembedded.fr/2018/08/openocd-from-scratch/.
L’Anti-débogage existe aussi!
Ptrace
strace, ltrace ou même GDB utilise ptrace en arrière plan, sans ce dernier; ces outils deviennent presque inutile.
Utiliser ptrace pour l'anti débogage
Une règle importante du débogage dit : “il ne peut y avoir qu'un seul débogueur attaché à un programme”, une erreur sera générée si nous essayons d'en connecter plus. Voici un exemple :
- (ptrace-anti-debug.c) : Voici un programme qui utilise ptrace pour signaler qu'il sera tracé par son parent (Le code est aussi disponible sur ce lien : https://github.com/jugurthab/Linux_kernel_debug/tree/master/debug-examples/Chap6-kernel-security/userspace/ptrace-antidebug). Ainsi, nous ne pourrons pas déboguer ce programme.
int main(){ if(ptrace(PTRACE_TRACEME , 0) < 0 ){ printf("You cannot debug me!\n"); exit(EXIT_FAILURE); } getchar(); printf("No debugger detected\n"); return EXIT_SUCCESS; } - Débogage avec GDB : Tentons d'attacher GDB et créer une session de débogage comme suit :
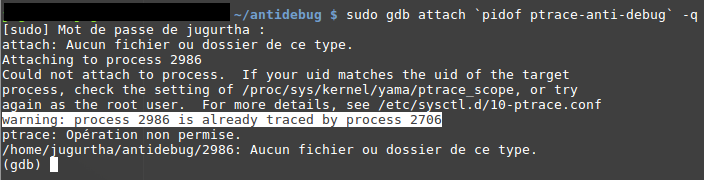
- Attacher GDB au programme : Cela veut dire qu'on doit lancer le programme puis attacher GDB.
- Démarrer le programme avec GDB : (voir l'image ci-dessous)

- Attacher GDB au programme : Cela veut dire qu'on doit lancer le programme puis attacher GDB.
GDB n'est pas capable de se connecter, car le processus distant est déjà en cours de débogage.
Contourner l’anti-débogage "ptrace"
Le débogage devient très difficile quand l'Anti-debug est employé. Cependant, dans ce cas; nous pouvons facilement contourner cette protection en sautant directement à la fonction getchar().
- Placez un point d'arrêt : afin de sauter à un emplacement donné, le programme doit être en cours d'exécution ce qui signifie que nous avons besoin d'au moins un point d'arrêt. Placez-le au début de la fonction ptrace et exécutez le programme :
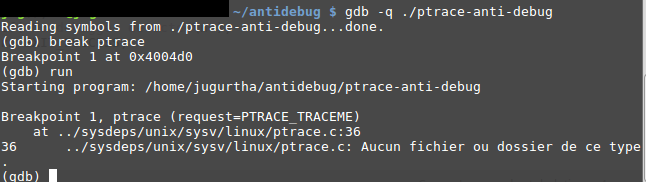
- il suffit d'afficher l'emplacement de getchar() en mémoire et d'y sauter en utilisant GDB:
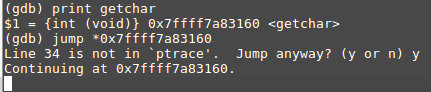
- Poursuivre l'exécution du programme : Au moment où nous avons fait le saut, un curseur clignotant attendait une entrée de caractère (c'est le comportement de getchar()), nous pouvons lui donner un caractère comme montré ci dessous :

LD_PRELOAD
est une variable d’environnement qui permet de lister les bibliothèques qu'on doit charger (ainsi que nos propres bibliothèques) pour le bon fonctionnement d'un exécutable. Lors de l'édition des liens, nous pouvons remplacer une bibliothèque par notre propre bibliothèque. Cette variable est à utiliser avec précaution pour des raisons que nous évoquons dans la suite.
Hacker avec LD_PRELOAD
Nous pouvons créer notre bibliothèque qui va ré-implémenter une fonctionnalité déjà fournie par la bibliothèque standard C mais dont le comportement est différent.
- Création d'un programme d'authentification
- programme de test (secure-program.c) : les sources sont disponible sur github.
Les sources de secure-program.c
Les sources sont disponible sur :
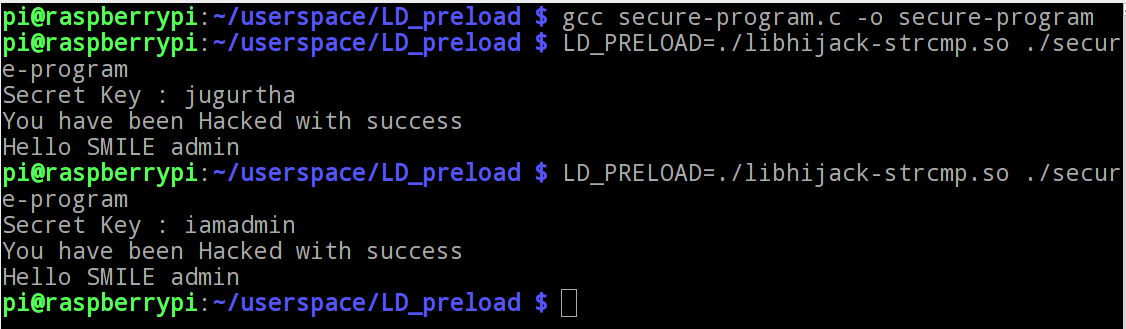
- Compilation et tests : (voir l'image ci-dessous).
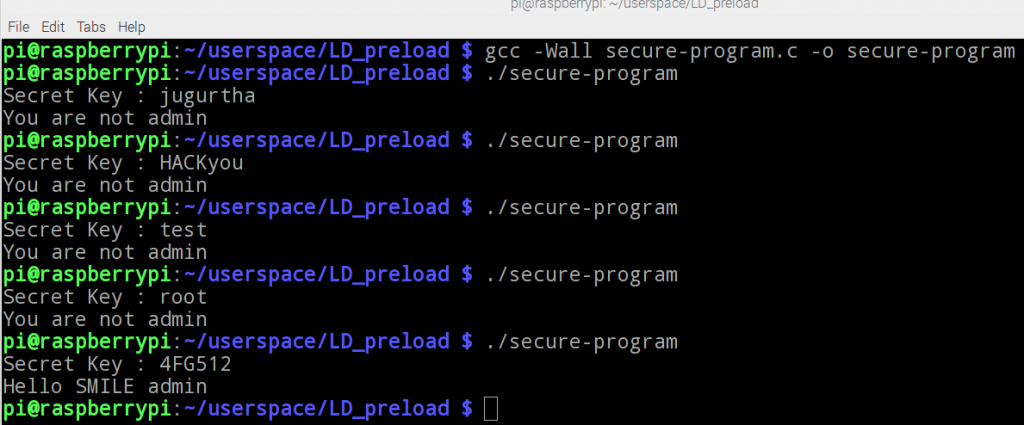
Notre programme fonctionne correctement et répond par "Hello SMILE admin" seulement quand le bon mot de passe est fourni.
- programme de test (secure-program.c) : les sources sont disponible sur github.
- Création d'une bibliothèque malicieuse
- library-code-strcmp.c : définit un autre comportement de strcmp :
int strcmp ( const char * str1, const char * str2 ){ printf("You have been Hacked with success\n"); return 0; } - Compilation de la bibliothèque
$ gcc -fPIC --shared -o libhijack-strcmp.so library-code-strcmp.c - Usage de LD_PRELOAD : nous pouvons à présent charger notre bibliothèque avec LD_PRELOAD comme suit :
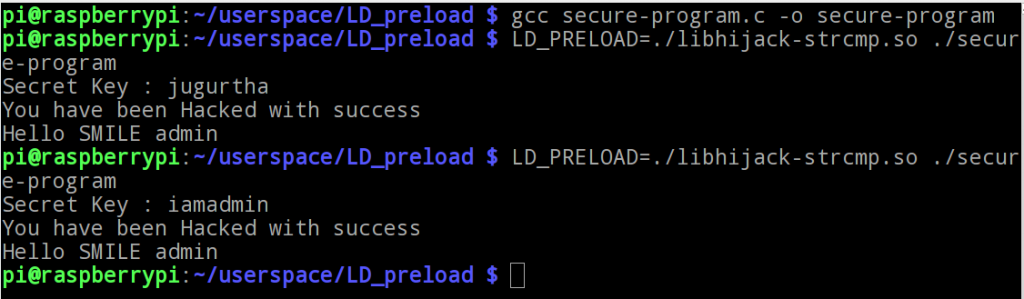
On peut noter que le programme accepte n'importe quel mot de passe.
- library-code-strcmp.c : définit un autre comportement de strcmp :
Détecter l'usage de LD_PRELOAD
Il est possible de traquer l'usage de LD_PRELOAD grâce aux artefacts que l'on peut trouver sur le système.
- Fichier Maps : le fichier maps retourne le chemin à partir duquel les bibliothèques sont chargées.
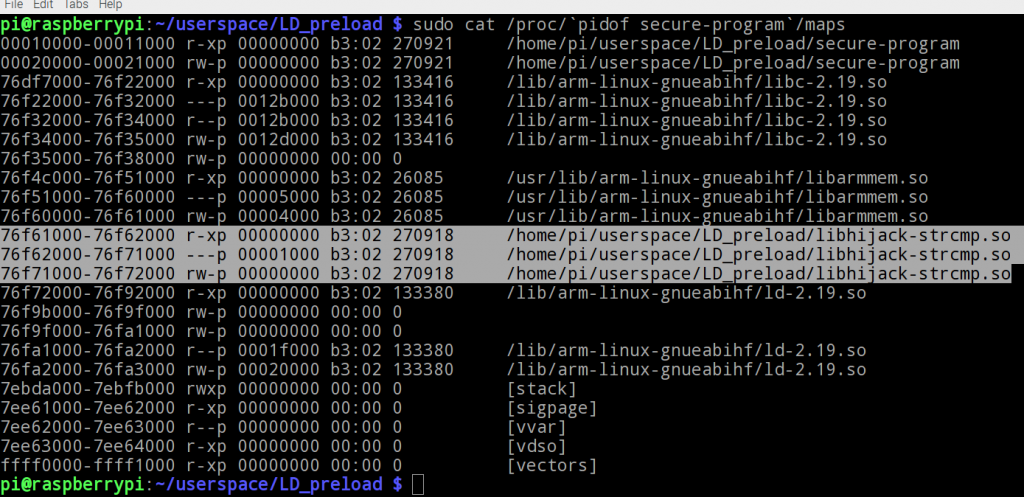
On constate rapidement que la bibliothèque libhijack-strcmp.so n'est pas chargée comme les autres (à partir de /lib/), ce qui est une forte indication de l'usage de LD_PRELOAD.
- Fichier variable d’environnement : affiche toutes les variables d’environnement associées à un processus comme ceci :

LD_PRELOAD est présente, ce qui confirme son usage.

Modules en feu
Le noyau est la cible la plus intéressante, on peut l'attaquer par plusieurs moyens mais on va présenter une manière d'infecter un module avec du code malicieux.
Création des modules
Nous devons créer deux modules. Le premier est bon (ne contient pas de code malicieux) , mais le deuxième est dangereux et on va l'injecter dans le premier.
- Module bon (kernel-module-safe.c) : un simple module qui affiche un message lors de son insertion (
$ sudo insmod kernel-module-safe.ko) et lors de son arrêt ($ sudo rmmod kernel-module-safe.ko)
static int __init mon_module_init(void) { printk(KERN_DEBUG "Hello SMILE, teach us OPEN SOURCE !\n"); return 0; } static void __exit mon_module_cleanup(void) { printk(KERN_DEBUG "Thank you SMILE!\n"); } module_init(mon_module_init); module_exit(mon_module_cleanup); - Module malicieux (kernel-module-to-inject.c) :
static int fake_init(void) __attribute__((used)); static int fake_init(void) { printk(KERN_DEBUG "Hacking is great!\n"); return 0; }Remarque : __attribute__((used)) force gcc à compiler une fonction qui n'est pas utilisée (sinon gcc va optimiser le code et supprimer notre méchante fonction)
Fusionner les deux modules
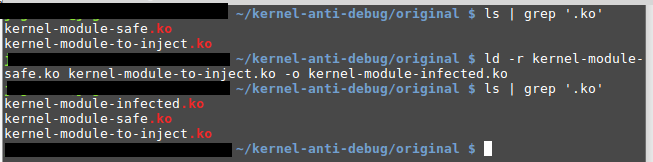
ld permet de combiner des modules comme suit :
$ ld -r kernel-module-safe.ko kernel-module-to-inject.ko -o kernel-module-infected.ko
Analyser le résultat de la fusion
La fusion génère un troisième module (kernel-module-infected.ko) qui contient les code des deux modules (kernel-module-safe.c et kernel-module-to-inject.c).
On peut l'analyser comme tous les fichiers ELF :
$ objdump -t kernel-module-infected.ko kernel-module-infected.ko: format de fichier elf32-i386 SYMBOL TABLE: ............ 00000000 l F .init.text 00000014 mon_module_init 00000000 l F .exit.text 00000012 mon_module_cleanup ............ ............ 00000014 l F .init.text 00000014 fak_module_init ............ ............ 00000000 g F .exit.text 00000012 cleanup_module 00000000 g F .init.text 00000014 init_module 00000000 *UND* 00000000 printk
Forcer init_module à exécuter fak_module_evil
Nous pouvons le faire manuellement (mais cela exige une bonne connaissance du format ELF), il existe un utilitaire qui permet de le faire "elfchger" (disponible sur : https://github.com/jugurthab/Linux_kernel_debug/tree/master/debug-examples/Chap6-kernel-security/kernel/module-tampering).
$ ./elfchger -s init_module -v 00000014 kernel-module-infected.ko
Cela produit le résultat suivant :
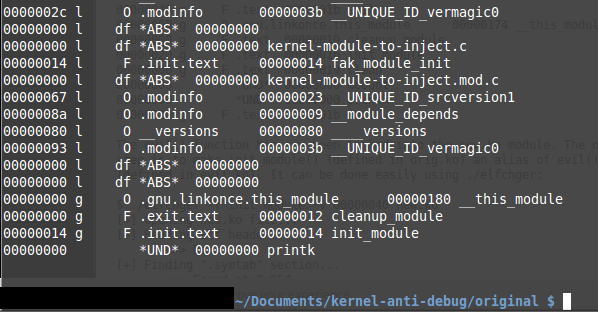
La ligne 00000014 g F .init.text 00000014 init_module indique que init_module pointe vers fak_module_init.
Insérer le module infecté dans le noyau
Il est temps d'injecter le module dans le noyau comme suit:

Eureka! La fonction malicieuse s'est exécutée et le message "Hacking is great!" est affiché.
Conclusion
Dans cet article, nous avons parcouru les outils de débogage dans l'espace utilisateur et noyau. Nous avons bien appréhendé l'utilité et l'utilisation de chaque méthode. Nous avons présenté également quelques éléments de sécurité, des techniques malicieuses qui doivent vous permettre de prendre consience de certains dangers, et d'adapter vos logiciels en conséquence.
N'oublions pas que la qualité logicielle s'appuie sur un processus de développement reproductible, de la documentation, des tests, de la relecture de code, etc.
A bientôt pour de nouvelles aventures, nous irons plus loin avec les traceurs Linux.
Article claire, simple et qui résume bien le sujet.